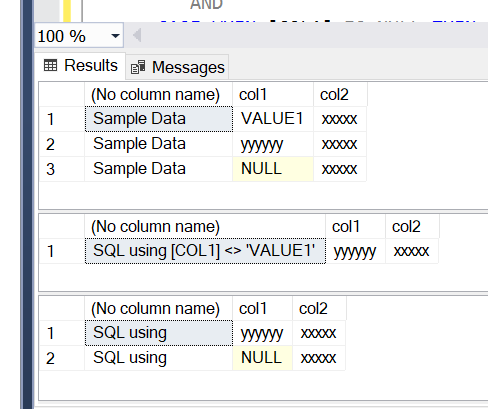
When Col1 is NULL, the first clause in your WHERE condition - COL1 <> 'VALUE1' evaluates to unknown. Hence the where clause returns UNKNOWN.
You can see this more clearly if you examine the following test snippet. It will tell you that @Col1 is equal to VALUE1, even though it clearly is not. This is because the WHEN condition does not evaluate to TRUE, it evaluates to UNKNOWN, and so the ELSE clause gets executed.
DECLARE @Col1 VARCHAR(32) = NULL;
SELECT
CASE
WHEN @Col1 <> 'VALUE1' THEN
'@Col1 is not equal to VALUE1'
ELSE
'@Col1 is equal to VALUE1'
END;
Lookup articles on how NULL behaves in SQL Server, for example here.
in the first SQLclause its ignoring nulls
in the second SQL NULL is showing up
please click arrow to the left for Drop Create Sample data
drop table #explaining
create table #explaining
(
col1 varchar(10) null ,
col2 varchar(10)
)
go
insert into #explaining select 'VALUE1' , 'xxxxx'
insert into #explaining select 'yyyyyy' , 'xxxxx'
insert into #explaining select Null , 'xxxxx'
go
select 'Sample Data',* from #explaining
select
'SQL using [COL1] <> ''VALUE1'' '
, *
from
#explaining
WHERE [COL1] <> 'VALUE1'
AND
CASE WHEN [COL1] IS NULL THEN [COL2] ELSE [COL1] END <> 'VALUE1'
select
'SQL using '
, *
from
#explaining
WHERE
CASE WHEN [COL1] IS NULL THEN [COL2] ELSE [COL1] END <> 'VALUE1'
False. NULLs add a level of complexity to value checking.
A NULL value is never = or <> any other value. After all, an unknown value could be 'VALUE1', so SQL can't say that it's "<>".
Also, a WHERE condition(s) must be "TRUE" to include a row, not just "might be TRUE" or "not proven FALSE".
Interestingly, a CHECK condition must be "FALSE" to prevent a row from being INSERTed. If you run the code below, you'll see that the NULL value IS inserted into #t1, even though it seems to break the CHECK constraint.
CREATE TABLE #t1 ( col1 varchar(10) NULL CHECK(col1 <> 'VALUE1') );
INSERT INTO #t1 VALUES('VALUE1') --<<-- not INSERTed
GO
INSERT INTO #t1 VALUES('VALUE2')
INSERT INTO #t1 VALUES(NULL) --<<-- this row *DOES* INSERT
SELECT * FROM #t1
GO
DROP TABLE #t1;
And then there are cases where null is interpreted as though NULL = NULL, as in the example below.
------------------------------------------------------------------
CREATE TABLE #tmp(id INT NULL UNIQUE)
-- this is successful
INSERT INTO #tmp VALUES (NULL);
-- this fails, because there is a NULL already, suggesting NULL=NULL.
INSERT INTO #tmp VALUES (NULL);
------------------------------------------------------------------
-- and then there is this
INSERT INTO #tmp VALUES (1),(2), (3);
-- where only two rows are returned even though there are four rows in the table
-- of which only one row has the value 1.
SELECT * FROM #tmp WHERE id NOT IN (1)
-----------------------------------------------------------------
-- and then even funnier, where the query returns nothing.
CREATE TABLE #tmp2( id INT NULL UNIQUE)
INSERT INTO #tmp2 VALUES (1),(NULL);
SELECT * FROM #tmp AS t
WHERE id NOT IN
( SELECT t2.id FROM #tmp2 AS t2 )
It is well-worth spending the time to learn the nuances of the 3-valued logic in SQL to avoid many associated pitfalls such as these. There are very rational explanations and exceptions to the explanations as to why the behaviors are the way they are.