select distinct student_ssn from stu_award sa join stu_award_year say on sa.stu_award_year_token=say.stu_award_year_token join student s on say.student_token=s.student_token join user_string us on say.student_token=us.student_token where say.award_year_token='2015' and sa.fund_ay_token <> '17313' and (us.value_171='000' or us.value_171='001')
I'm getting results returned where sa.fund_ay_token DOES EQUAL 17313. I want to exclude any row where sa.fund_ay_token IS EQUAL to 17313.
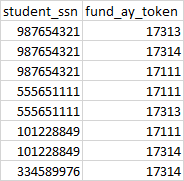
The query as you have written should not return rows in which sa.fund_ay_token = 17313. Is it possible that there is more than one row for a given student_ssn and some of those have fund_ay_token <> 17313? Include the sa.fund_ay_token in the select list and see what you get.
SELECT DISTINCT
student_ssn,
sa.fund_ay_token ---< FOR TESTING
FROM stu_award sa
JOIN stu_award_year say ON sa.stu_award_year_token = say.stu_award_year_token
JOIN student s ON say.student_token = s.student_token
JOIN user_string us ON say.student_token = us.student_token
WHERE say.award_year_token = '2015'
AND sa.fund_ay_token <> '17313'
AND ( us.value_171 = '000'
OR us.value_171 = '001'
)
I'm looking for it to return any student who has a 001 or a 000 in us.value_171 but who does NOT have a 17313 in the fund_ay_token. Each student_ssn can have multiple fund_ay_tokens.
If your objective is to return only student_ssn's for which there are no rows that have sa.fun_ay_token = 17313 (even though some other rows may have sa.fun_ay_token <> 17313), you should use a not exists clause. From the query it is not clear to me which table has student_ssn.. Assuming that it is in student_ table, then, the query would be something like this:
SELECT DISTINCT
student_ssn
FROM
student s
INNER JOIN stu_award_year say ON
say.student_token = s.student_token
INNER JOIN user_string us ON
say.student_token = us.student_token
WHERE
say.award_year_token = '2015'
AND
(
us.value_171 = '000'
OR us.value_171 = '001'
)
AND NOT EXISTS
(
SELECT * FROM stu_award sa
WHERE
sa.stu_award_year_token = say.stu_award_year_token
-- AND sa.student_token = s.student_token -- Perhaps you don't need this condition.
AND sa.fund_ay_token = '17313'
);
What you posted does not look valid. Or relational.
Rows are not records. This is usually covered the first week of any RDBMS class, so when someone makes an error that fundamental, I get a really bad feeling. Would you go to a doctor who talks about “balancing your humours” with blood letting” or leave?
Since 85 to 95% of the work in SQL and RDBMS is in the DDL, we need to see it. This has been minimal Netiquette for 30+ years
Tables model sets, so their names are plural or collective nouns, but you have singular names.
A year is unit of temporal measurement, but you put it in a table. Is there a table of liters, kilograms and other units of measure? This ought to be an attribute of Student_Awards, but we have no DDL because you did not follow forum rules about DDL.
User_Strings is an absurd data element name. A “string” is a type of meta data. We want to know what is modeled with a string as opposed to numeric, as opposed to a temporal, etc.
SQL programmers do not write COBOL or BASIC style OR-ed chains; we use “US.value_171 IN ('000', '001')” instead.
Why do you think that “value_171” follows ISO-11179 rules? It looks like a fake one-dimensional array.
SELECT DISTINCT is rare in a normalized database. The DRI constraints (again, where is the DDL?) guarantee matches and prevent redundancy.
What kind of entity is a “token”? What magic does it have to be able to change from students to a year? Can it be a squid or an automobile?
Code below will usually perform better, getting more noticeable as the dataset gets larger:
SELECT student_ssn
FROM stu_award sa
INNER JOIN stu_award_year say on sa.stu_award_year_token=say.stu_award_year_token
INNER JOIN student s on say.student_token=s.student_token
INNER JOIN user_string us on say.student_token=us.student_token
GROUP BY student_ssn
HAVING MAX(CASE WHEN say.award_year_token='2015' and (us.value_171='000' or us.value_171='001') THEN 1 ELSE 0 END) = 1 AND
MAX(CASE WHEN sa.fund_ay_token = '17313' THEN 1 ELSE 0 END) = 0
I apologize for not following proper "Netiquette". I'm not well-versed in the proper "language" here. Fortunately, I've only encountered folks on this forum who've been great at helping explain things I do not understand. I appreciate constructive criticism. It may be worthwhile to mention that the tables I'm pulling data from in this script are not my tables. They are the tables from software that I have no control over. I do not control their names or the majority of the data in them, such as the "year" you mention in #4 of your response. Same goes for #5. I didn't create the table, the vendor did. For #6, I'm not a SQL programmer, but I'm trying to do the best I can. For #8, you'd have to see the database to understand why I need distinct values. For #9, again, I didn't create the naming convention for this database.
Thank you, Scott! Your solution worked perfectly! I modified it to look at the award year from the "user_string" table rather than from the "stu_award_year" table, and am getting exactly the results I needed. I appreciate your help!
Btw, you have two logical possibilities, and they might give different results.
The HAVING condition as written, like this: HAVING MAX(CASE WHEN say.award_year_token='2015' and (us.value_171='000' or us.value_171='001') THEN 1 ELSE 0 END) = 1
requires the same row to have year 2015 and value_171 of 000 or 001. If you want to match the student even if those values are on different rows -- which I didn't think was likely here but is certainly possible -- you would do this:
HAVING MAX(CASE WHEN say.award_year_token='2015' THEN 1 ELSE 0 END) = 1 AND
MAX(CASE WHEN us.value_171='000' or us.value_171='001' THEN 1 ELSE 0 END) = 1
"I do not drive the train. I cannot ring the bell. But let the damn thing jump the track and I am the guy who catches hell!" -- old IT poem
A lot of software packages are awful code. I recently heard of one without any indexing. I worked for a failed dot-com that used GUIDs for all the keys. I have seen a schema without DRI, so it filled with orphan rows and chocked a disk drive. Pick your horror story.
This stinks of attribute splitting -- what should be a column in one table is spread into its own table -- think about having a "Male_Personnel" and "Female_Personnel" by splitting "Personnel" on the sex code. And there is nothing you can do about a bad schema. Try JamesK's suggestion and see if it works.
 -- old IT poem
-- old IT poem