Hi, I am trying to combine 2 queries that are counting records, but the output is confusing me.
The queries, individually, simply count how many records match a criteria, and they work individually. But when I combine them via union, the totals are changing. I have tried union all. The data for both queries is in the same table.
Basically, my query is counting how many people have done training, vs how many people havent, and I need it in a 2 column, 2 row format. I need it in this format for an Apex chart. The criteria is literally the opposite of each other.
SELECT 'Completed' AS TEXT
, COUNT(*) AS TOTAL
FROM table1
WHERE training = 'Completed'
UNION ALL
SELECT 'Not Completed' AS TEXT
, COUNT(*) AS TOTAL
FROM table1
WHERE training != 'Completed' indent preformatted text by 4 spaces
Looks fine when i do it from Transact SQL .. SSMS Editor
Maybe your software ?? glitch .. or may be 100 different things
As usual have to debug being software people
Pain in the ....
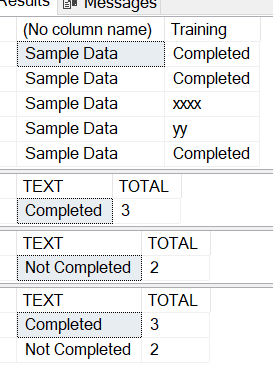
drop table #table1
create table #table1
(
Training varchar(100)
)
insert into #table1 select 'Completed'
insert into #table1 select 'Completed'
insert into #table1 select 'xxxx'
insert into #table1 select 'yy'
insert into #table1 select 'Completed'
select 'Sample Data',* from #table1
SELECT 'Completed' AS TEXT , COUNT(*) AS TOTAL FROM #table1 WHERE training = 'Completed'
SELECT 'Not Completed' AS TEXT , COUNT(*) AS TOTAL FROM #table1 WHERE training != 'Completed'
SELECT 'Completed' AS TEXT , COUNT(*) AS TOTAL FROM #table1 WHERE training = 'Completed'
UNION ALL
SELECT 'Not Completed' AS TEXT , COUNT(*) AS TOTAL FROM #table1 WHERE training != 'Completed'
I suspect you are getting confused with 3 value logic when training is NULL:
CREATE TABLE #t
(
training varchar(20) NULL
);
INSERT INTO #t
VALUES('Completed'),('Start'),(NULL),('End');
select * from #t;
SELECT COUNT(*)
FROM #t
WHERE training = 'Completed';
SELECT COUNT(*)
FROM #t
WHERE training != 'Completed';
SELECT COUNT(*)
FROM #t
WHERE training != 'Completed'
OR training IS NULL;
You probably want:
SELECT X.[Text]
,COUNT(1) AS Total
FROM #t T
CROSS APPLY
(
VALUES
(
CASE
WHEN T.training = 'Completed'
THEN 'Completed'
ELSE 'Not completed'
END
)
) X ([Text])
GROUP BY X.[Text]
Maybe I am missing something - but this seems to be a simple grouping:
Select text = Case When t.Training = 'Completed' Then 'Completed' Else 'Not Completed' End
, total = count(*)
From table1 t
Group By
Case When t.Training = 'Completed' Then 'Completed' Else 'Not Completed' End;
For some reason, that produces totals that are way off, more than triple what they should be. I believe I have found a solution and it involves the unpivot function.