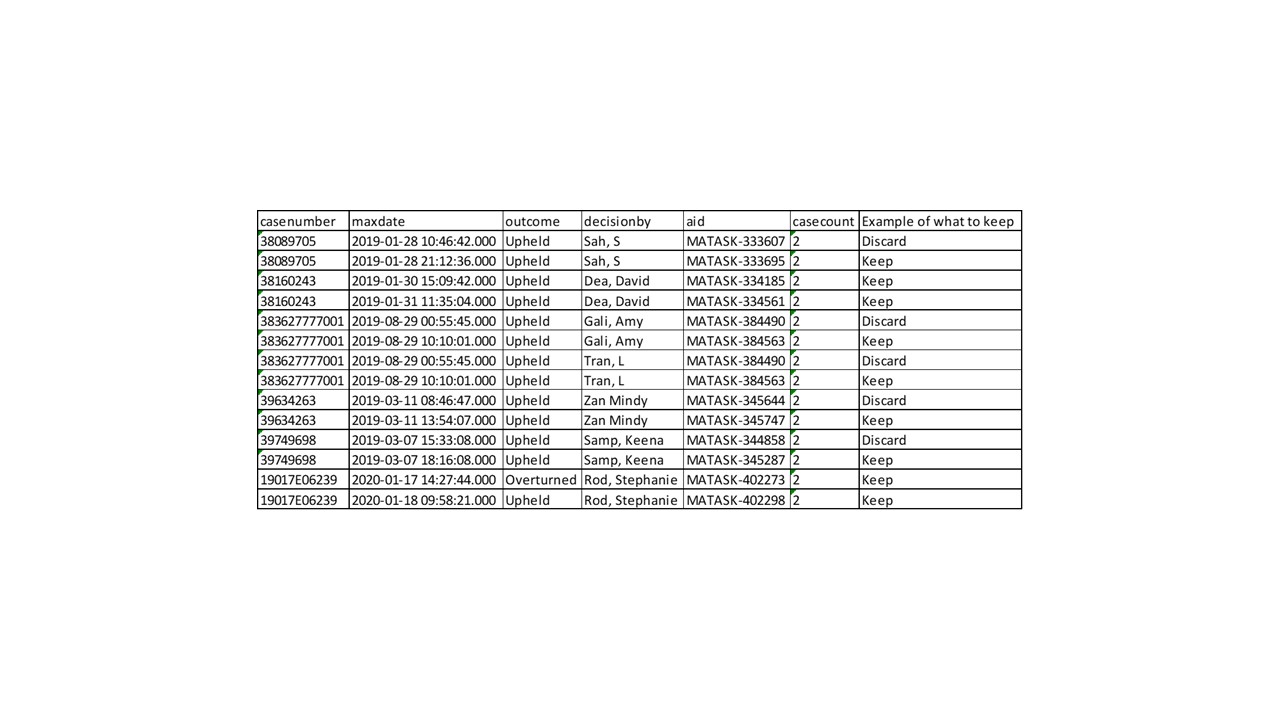
I am having a super tough time trying to figure out how to place a flag on what I should keep and should not keep. Below is an example of the 1009 rows I have. I tried doing a case count on the case number and that helped with where the case number shows up more than 3 times for a decision by and was able to delete the duplicates that way where the max date is the same day but varying timestamp. I cannot get rid of the timestamp and the reason is that the outcome says for 38089705 might be overturned on the 2nd row. The day is the same but the stamp varies and I need to take the last of that stamp. Where the day of something is the same day I take the max of that max date but where it is the next day or beyond I keep them all. So you see for example 38160243 I would keep both rows even though the case number same and the decision by same and outcome same but the records were touched on different days. I just am not sure how to code this so I can easily keep what is not a dupe in the eyes of corporate-like 38160243 and then get rid of a dupe in the eyes of the corporate which would be row 1 below for that case number. I am manually doing it now. Where I get the case count and started with 1, 3, and up and ran a delete on what I needed but now to =2 and 947 rows left and eyeballing this is nuts. The coding for this is just not in my brain maybe because I have spent 4 hours researching how to fix and hitting a roadblock. I posted an example in a .jpg of the data.
Please post directly usable data. That is, a CREATE TABLE and INSERT statement(s) that produce the data above in a table. That way we can develop code using the data. We can't use data in a picture 
create table TinaTest (
CaseNumber varchar(25),
FinalDecisionDate datetime,
OutComeCategory varchar(25),
DecisionBy varchar(150),
AID varchar(50))
insert into TinaTest values('0011126312','2019-01-22 07:21:56.000','Overturned','Iddings, Emily A.','MATASK-328247')
insert into TinaTest values('0011126312','2018-11-09 07:07:14.000','Upheld','Iddings, Emily A.','MATASK-312420')
insert into TinaTest values('0086214','2020-06-23 18:34:56.000','Upheld','Dearworth, David','MATASK-422873')
insert into TinaTest values('0086214','2020-06-23 18:36:58.000','Upheld','Dearworth, David','MATASK-422874')
insert into TinaTest values('0261803423','2019-05-13 11:32:35.000','Upheld','Johnson, Jessica','MATASK-362142')
insert into TinaTest values('0261803423','2019-06-24 14:51:48.000','Upheld','Johnson, Jessica','MATASK-372330')
insert into TinaTest values('107992582','2019-02-16 06:34:23.000','Overturned','Porterfield, Michelle','MATASK-339664')
insert into TinaTest values('107992582','2019-02-16 06:45:13.000','Overturned','Porterfield, Michelle','MATASK-339668')
select * from operadatadev.dbo.TinaTest order by casenumber asc
So with this data set the request is the keep any casenumber that is duplicated where the rest of the columns are not if the FinalDecisionDate is not the same day. If the FinalDecisionDate is the same day, then it is the max of that timestamp. In this case of the above if I do a casenumber asc and do this as row count, I would keep the following rows: 1, 2, 4, 5, 6, 8. I am just trying to write some sort of flag statement to say what I keep and what I do not like maybe flag 1 as keep and 0 as don't keep. I tried doing a max of the date but then it gets rid of row 2 and row 5 but those are valid because different days. I only want to do the max of the date where the date is the same day and do max of that timestamp and that is the record I keep in that case. If the casenumber is same and date varies, I keep those.
select *
from (
select *, ROW_NUMBER() OVER (
PARTITION BY CaseNumber, cast(FinalDecisionDate as date)
ORDER BY FinalDecisionDate
) row_num
from @TinaTest
) a
where row_num = 1
Oh wow thank you. This looks great.