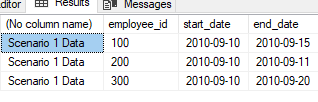
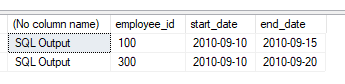
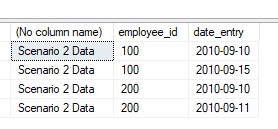
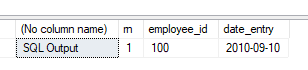
SQL Server 2008:
--alter proc question as
declare @t table (scanCode varchar(6), dates datetime, flag varchar(1))
insert @t ( scanCode, dates, flag)
select '182086','01 Jul 2020','P' union all
select'182086','02 Jul 2020','P' union all
select'182086','03 Jul 2020','A' union all
select'182086','04 Jul 2020','A' union all
select'182086','06 Jul 2020','P' union all
select'182086','07 Jul 2020','P' union all
select'182086','08 Jul 2020','P' union all
select'182086','09 Jul 2020','P' union all
select'182086','10 Jul 2020','A' union all
select'182086','11 Jul 2020','A' union all
select'182086','13 Jul 2020','A' union all
select'182086','14 Jul 2020','A'
select scanCode
, dates
, flag
, prn = row_number() over (partition by scanCode,flag order by scanCode, dates)
from @t t
order by t.dates
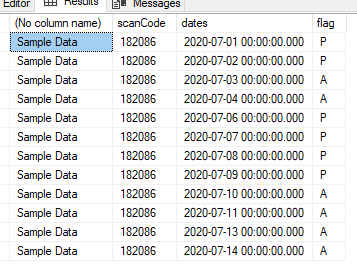
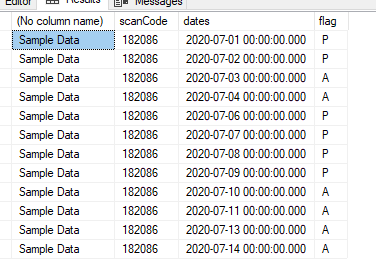
--currently the result is
/*
scanCode dates flag prn
182086 2020/07/01 P 1
182086 2020/07/02 P 2
182086 2020/07/03 A 1
182086 2020/07/04 A 2
182086 2020/07/06 P 3
182086 2020/07/07 P 4
182086 2020/07/08 P 5
182086 2020/07/09 P 6
182086 2020/07/10 A 3
182086 2020/07/11 A 4
182086 2020/07/13 A 5
182086 2020/07/14 A 6
*/
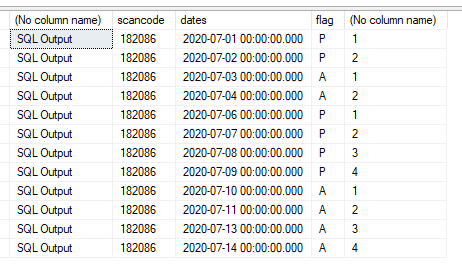
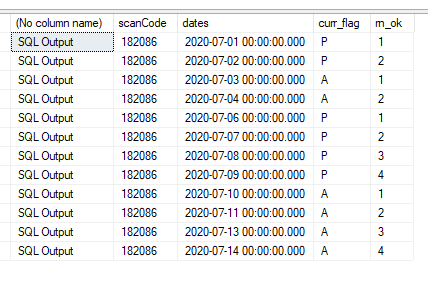
-- I want the result to be
/*
scanCode dates flag prn
182086 2020/07/01 P 1
182086 2020/07/02 P 2
182086 2020/07/03 A 1
182086 2020/07/04 A 2
182086 2020/07/06 P 1
182086 2020/07/07 P 2
182086 2020/07/08 P 3
182086 2020/07/09 P 4
182086 2020/07/10 A 1
182086 2020/07/11 A 2
182086 2020/07/13 A 3
182086 2020/07/14 A 4
*/