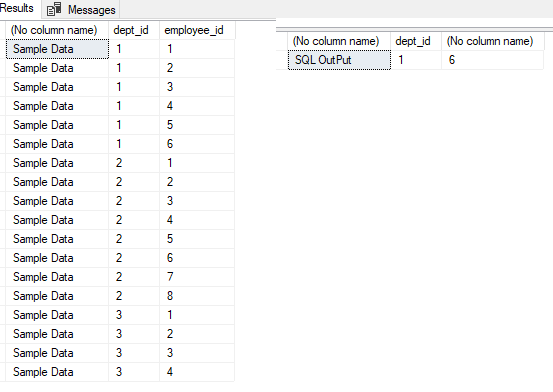
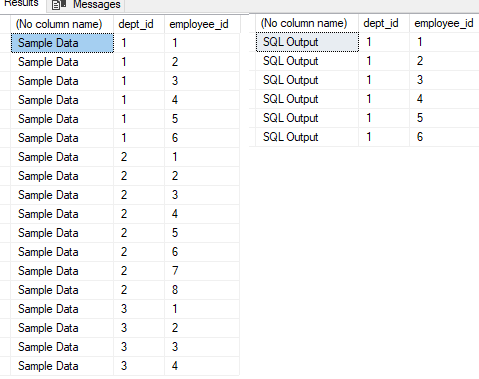
Without any schema definition and sample data, it will be just a guess
select count(1)
from vEmployeeDepartment d
where exists(
select 1
from vEmployeeDepartment tgt
where d.departmentId = tgt.departmentId
group by EmployeeId
HAVING count(1) = 6
)
drop table #SampleData
go
create table #SampleData
(
dept_id int
,employee_id int
)
go
insert into #SampleData select 1,1
insert into #SampleData select 1,2
insert into #SampleData select 1,3
insert into #SampleData select 1,4
insert into #SampleData select 1,5
insert into #SampleData select 1,6
insert into #SampleData select 2,1
insert into #SampleData select 2,2
insert into #SampleData select 2,3
insert into #SampleData select 2,4
insert into #SampleData select 2,5
insert into #SampleData select 2,6
insert into #SampleData select 2,7
insert into #SampleData select 2,8
insert into #SampleData select 3,1
insert into #SampleData select 3,2
insert into #SampleData select 3,3
insert into #SampleData select 3,4
go
select 'Sample Data',* from #SampleData
go
SELECT
'SQL OutPut'
, [#SampleData].[dept_id]
, COUNT(DISTINCT [#SampleData].[employee_id])
FROM
[#SampleData]
GROUP BY
[#SampleData].[dept_id]
HAVING
COUNT(DISTINCT [#SampleData].[employee_id]) = 6;
; with cte as
(
SELECT
[#SampleData].[dept_id]
, COUNT(DISTINCT [#SampleData].[employee_id]) as cnt_dis
FROM
[#SampleData]
GROUP BY
[#SampleData].[dept_id]
HAVING
COUNT(DISTINCT [#SampleData].[employee_id]) = 6
)
select a.* from #SampleData a join cte b on a.dept_id = b.dept_id
I think this will work, but I don't have any way to test it since you didn't post any usable test data.
SELECT count(distinct Department)
--Department as [Department Name]
FROM HumanResources.vEmployeeDepartment
GROUP BY Department
HAVING count(Department) = 6
select count(Distinct Department) from (
select Department, count(1) N
--Department as [Department Name]
from HumanResources.vEmployeeDepartment
GROUP BY Department
HAVING count(1) = 6) x
Scott, your code produced multiple records. OP wanted a count of departments that had employees.
create table #SampleData
(
dept_id int
,employee_id int
)
go
insert into #SampleData select 1,1
insert into #SampleData select 1,2
insert into #SampleData select 1,3
insert into #SampleData select 1,4
insert into #SampleData select 1,5
insert into #SampleData select 1,6
insert into #SampleData select 2,1
insert into #SampleData select 2,2
insert into #SampleData select 2,3
insert into #SampleData select 2,4
insert into #SampleData select 2,5
insert into #SampleData select 2,6
insert into #SampleData select 2,7
insert into #SampleData select 2,8
insert into #SampleData select 3,1
insert into #SampleData select 3,2
insert into #SampleData select 3,3
insert into #SampleData select 3,4
insert into #SampleData select 3,5
insert into #SampleData select 3,6
SELECT count(distinct dept_id)
--Department as [Department Name]
FROM #SampleData
GROUP BY dept_id
HAVING count(dept_id) = 6
select count(Distinct dept_id) from (
select dept_id, count(1) N
--Department as [Department Name]
from #SampleData
GROUP BY dept_id
HAVING count(1) = 6) x