Hello,
I was hoping for some guidance for transposing data rows to columns as I have tried several code snippets online but to no avail alas. I am using SQL 2016.
My query produces the table below:
Query:
select distinct
pe.pat_enc_csn_id, PROC_START_TIME
from
pat_enc pe
inner join
order_proc op on pe.pat_enc_csn_id = op.pat_enc_csn_id
inner join
clarity_eap eap on EAP.PROC_ID = op.PROC_ID
where
op.PROC_START_TIME>= '2022-07-26'
and eap.proc_Name like '%restraint%behavioral%'
order by
pat_enc_csn_id
Output:
pat_enc_csn_id PROC_START_TIME**
-------------------------------
1 7/26/22 1:00 PM
1 7/26/22 1:48 PM
2 7/26/22 1:06 PM
2 7/26/22 1:18 PM
3 7/26/22 9:25 AM
3 7/26/22 1:15 PM
4 7/26/22 1:17 PM
5 7/26/22 12:32 AM
However, I need the proc start time to be transposed to columns. Also, each encounter can have an unlimited number of columns and must be sorted by first time to last time.
pat_enc_csn_id PROC_TIME_1 PROC_TIME_2
-------------------------------------------------------
1 7/26/22 1:00 PM 7/26/22 1:48 PM
2 7/26/22 1:06 PM 7/26/22 1:18 PM
3 7/26/22 9:25 AM 7/26/22 1:15 PM
4 7/26/22 1:17 PM
5 7/26/22 12:32 AM
Any advice or guidance would be greatly appreciated.
Many thanks!
If this is for a report or similar visual representation, you're better off doing this in a reporting tool like SQL Server Reporting Services, such as a Matrix report.
SQL Server has a PIVOT operator that can do some basic transposition, but it's not dynamic, you'd have to define the maximum number of pivoted columns, or you'd have to use dynamic SQL to determine them and then generate the correct SQL.
1 Like
I think the code below will work, although I didn't have any usable data to test it with.
select
pat_enc_csn_id,
max(case when row_num / 2 = 1 then PROC_START_TIME end) as proc_time_1,
max(case when row_num / 2 = 0 then PROC_START_TIME end) as proc_time_2
from (
select distinct
pe.pat_enc_csn_id, PROC_START_TIME,
row_number() over(partition by pe.pat_enc_csn_id order by pe.proc_start_time) as row_num
from
pat_enc pe
inner join
order_proc op on pe.pat_enc_csn_id = op.pat_enc_csn_id
inner join
clarity_eap eap on EAP.PROC_ID = op.PROC_ID
where
op.PROC_START_TIME>= '2022-07-26'
and eap.proc_Name like '%restraint%behavioral%'
) as derived
group by pat_enc_csn_id, row_num / 2
Thank you so much for your help. That query generated the following:
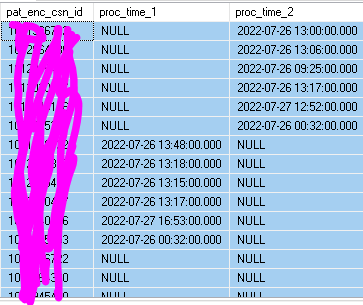
Does that look how you were expecting?
Thanks again.
the row_num / 2 in the group by is the reason for this, I think you can remove it without any error as it is in the aggregate MAX statement.
1 Like
@RogierPronk and @ScottPletcher thank you so much for helping me with this query. Dropping the extra field in the group by statement worked!!
I have one more question if you don't mind. Assuming each row could have 20+ proc start times, is there a reference as to how I code those additional row numbers in addition to making sure they display in ascending order? I tried searching online but not finding anything that explains what to put for additional rows.
That's what my code was designed to handle: mutliple proc start times for the same csn_id.
But without out directly usable sample data, I wasn't able to test it / debug it to see why it isn't handling that.
1 Like