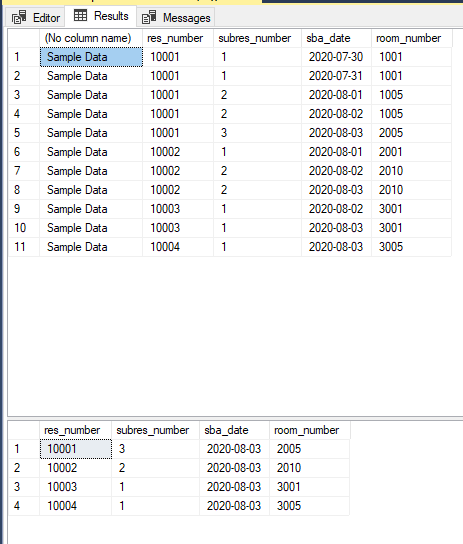
So, let's say that I have a table called "res_table" and it has the below columns and data. How would I grab the latest entry for each reservation from this table?
Cost is irrelevant here - what you need to look at is the actual time and IO stats to determine which one will be better, and it all depends on how it will be used in the overall query.
In some cases - the row number version will perform better - it others the TOP 1 version will perform better. Again, it all depends on how it is incorporated into the overall query and the specific time and IO stats for that query.
they were almost identical in IO and time. The only difference I saw was the Top 1 had a second sort. When I ran them together, the first one took 34-36% of the process, while the second was 64-66%
Since the IO and time is almost identical - then either method will work. Testing of each version in the overall query will help to determine which is better for that query - at this time.
Just to be clear - I had a fairly complex query where I used the row_number() version to identify the latest rows in a CTE. In fact, in that query I had 2 CTE's and both used the row_number() version...then I modified the code to use the TOP 1 version and saw a significant improvement in performance.
In another case - I had to revert from the TOP 1 version to the row_number() version to improve overall performance.
Either way - the only way to be sure which one is better is to test each one.
Careful Mike... you cannot rely on % of Batch in the execution plan to choose which is the better code even if it's an Actual Execution plan because even Actual Execution plans are rife with estimates. As others have said, only a measure of actual runtime statistics will ultimately identify which is better and you have to be careful even then.