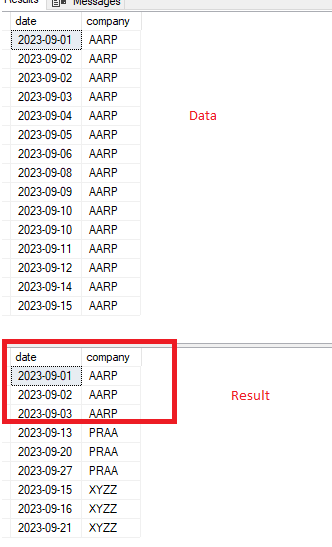
I am trying to capture the top 10 records for each date and company combination. The data listed below a very,very small sample. The dataset is over 100,000 records spanning over two years worth of dates There are 17 different companies information. I am using SSMS
9/20/2023 AARP
9/27/2023 AARP
9/13/2023 AARP
9/20/2023 AARP
9/20/2023 AARP
9/27/2023 PRAA
9/13/2023 PRAA
9/20/2023 PRAA
9/27/2023 PRAA
9/13/2023 PRAA
9/20/2023 PRAA
9/27/2023 PRAA
9/13/2023 XYZZ
9/20/2023 XYZZ
9/27/2023 XYZZ
9/13/2023 XYZZ
9/20/2023 XYZZ
I want to obtain the top 10 distinct records for each combination of date and company. I've tried tons ot the suggested codes out there but none of the will provide me with the results I need. Here is a sample of the output needed.
9/20/2023 AARP
9/27/2023 AARP
9/27/2023 PRAA
9/13/2023 PRAA
9/13/2023 XYZZ
9/20/2023 XYZZ
I posted this question on another forum,stackoverflow-questions-78233367-sql-select-top-10-records-for-each-two-columns-combination They closed the ticket without answering the question.