Hello all
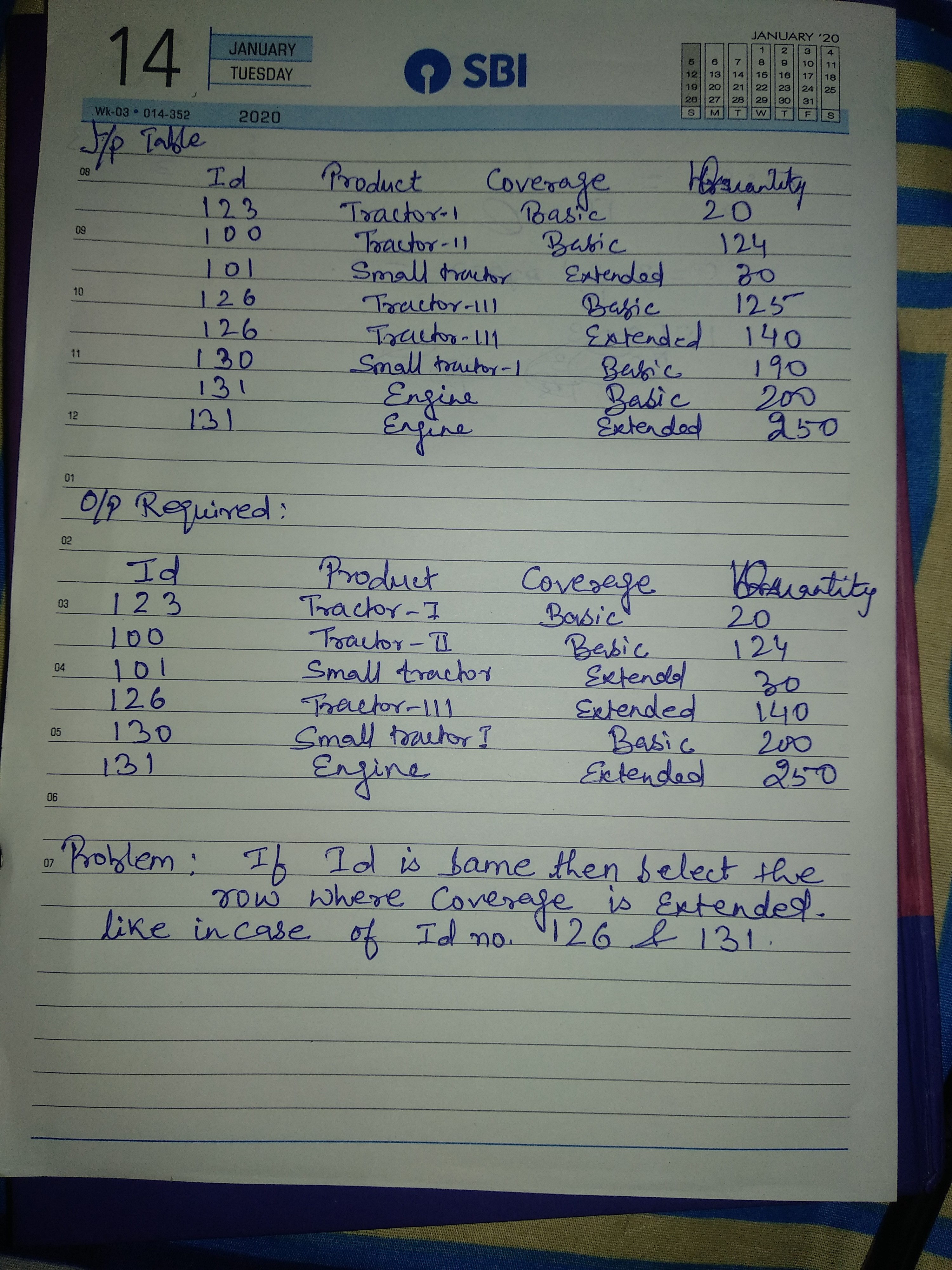
I need support with SQL code.. Actually I my dataset I have few duplicates id and I want to remove the one where coverage is basic if the Id is duplicate. In my attachment,I provided the input table and the output table which I am really looking for.
Can any one help with the code.
Welcome. How is work at Bank of India? very cute picture but would prefer if you provided proper DDL and DML
declare @a table(id int, product varchar(50), coverage varchar(50),
QUantity int )
insert into @
select 123, 'a', 'b', 1
etc
hi
hope this helps ..
drop table #sample_data
create table #sample_data
(
id int ,
product varchar(20),
coverage varchar(20),
Quantity int
)
go
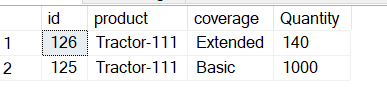
insert into #sample_data select 126,'Tractor-111','Basic',125
insert into #sample_data select 126,'Tractor-111','Extended',140
insert into #sample_data select 125,'Tractor-111','Basic',1000
go
; with cte as
(
select
id
, max(coverAGE) as maxcov
from
#sample_data
group by id
)
select
a.*
from
#sample_data A
join
cte b
on A.id = B.id and A.coverage = B.maxcov
1 Like
All depends on how the data is .. ( i mean data scenarios )
if its always duplicates and Basic and Extended then my SQL is valid
other wise
Some other SQL needs to be written ..