I needed help a couple of weeks ago and this place was great. So I figured the best way to learn SQL is to build a test program that I can add to as I need it. That way I'm not only looking at SQL when I'm working.
I am using SQL Server Compact 4.x. Right now my test program has 3 tables (tblDepartment, tblEmployee and tblEmail). tblEmployee has a foreign key to tblDepartment and tblEmail has a foreign key going to tblEmployee. Every employee is assigned a department id. Not every employee has an email address on record.
I am trying to get a list of all employees, their department and, if they have an email address, that information. But I want all employees. I thought this would be a case where I would use Left Outer Join. If it is then I'm doing something wrong. I'm only receiving employees who have an email address.
Here is my select statement:
SELECT e.empId AS [employeeId], e.empFName AS [employeeFirstName],
e.empLName AS [employeeLastName], em.emlId AS [emailId],
em.emlAddress AS [emailAddress], d.depId AS [departmentId],
d.depName AS [departmentName]
FROM tblEmployee e INNER JOIN tblDepartment d ON e.depID = d.depID
LEFT OUTER JOIN tblEmail em ON e.empID = em.empID
WHERE e.empId > 1 AND d.depId > 1 AND em.emlId > 1
ORDER BY e.empLName ASC, e.empFName ASC
Here is an image of the result I get:
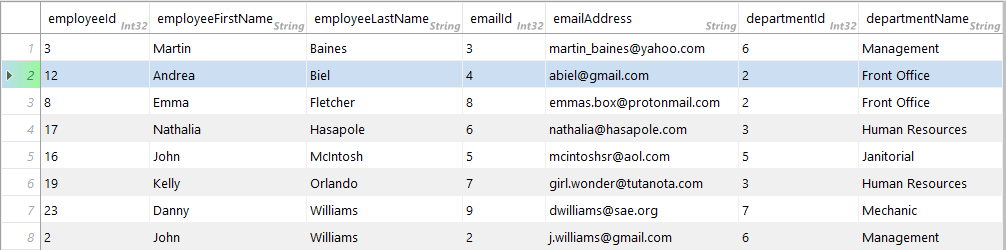
I've seen in some threads where people say it is helpful to include database table informaton (schema and data). I hope I understood that correctly. Here are the scripts for my current database (it's sql server compact... I don't know if that makes a difference).
tblDepartment:
CREATE TABLE [tblDepartment] (
[depId] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[depName] nvarchar(35) NOT NULL
)
GO
tblEmployee:
CREATE TABLE [tblEmployee] (
[empId] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[depId] int NOT NULL DEFAULT 1,
[empFName] nvarchar(35) NOT NULL,
[empLName] nvarchar(50) NOT NULL,
FOREIGN KEY ([depId])
REFERENCES [tblDepartment] ([depId])
ON UPDATE CASCADE ON DELETE CASCADE
)
GO
tblEmail:
CREATE TABLE [tblEmail] (
[emlId] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[empId] int NOT NULL,
[emlAddress] nvarchar(50) NOT NULL,
FOREIGN KEY ([empId])
REFERENCES [tblEmployee] ([empId])
ON UPDATE CASCADE ON DELETE CASCADE
)
GO
For the data I included the primary keys because there are 1 or 2 where I deleted a record and I didn't want the keys to not match. I hope that is alright.
tblDepartment data:
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (1,N'Temp Department');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (2,N'Front Office');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (3,N'Human Resources');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (4,N'Driver');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (5,N'Janitorial');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (6,N'Management');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (7,N'Mechanic');
GO
INSERT INTO [tblDepartment] ([depId],[depName]) VALUES (8,N'Landskeeping');
GO
tblEmployee data: (note that employee ID 4 has a single quote in her last name)
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (1,1,N'Temp',N'Employee');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (2,6,N'John',N'Williams');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (3,6,N'Martin',N'Baines');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (4,2,N'Wendy',N'O''Neal');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (5,6,N'Steve',N'Jennings');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (6,8,N'Dennis',N'Alscott');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (7,6,N'Caroline',N'Corr');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (8,2,N'Emma',N'Fletcher');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (9,5,N'Joanne',N'Murphy');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (10,8,N'Michael',N'Bridge');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (11,5,N'Rick',N'Scott');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (12,2,N'Andrea',N'Biel');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (13,4,N'Anthony',N'Umberton');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (14,2,N'Lacy',N'Nichols');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (16,5,N'John',N'McIntosh');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (17,3,N'Nathalia',N'Hasapole');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (18,4,N'Dave',N'Fisher');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (19,3,N'Kelly',N'Orlando');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (20,8,N'Carlos',N'Ortiz');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (21,7,N'Micah',N'Brandt');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (22,3,N'Kim',N'Connely');
GO
INSERT INTO [tblEmployee] ([empId],[depId],[empFName],[empLName]) VALUES (23,7,N'Danny',N'Williams');
GO
tblEmail data:
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (1,1,N'Temp Email Address');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (2,2,N'j.williams@gmail.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (3,3,N'martin_baines@yahoo.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (4,12,N'abiel@gmail.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (5,16,N'mcintoshsr@aol.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (6,17,N'nathalia@hasapole.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (7,19,N'girl.wonder@tutanota.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (8,8,N'emmas.box@protonmail.com');
GO
INSERT INTO [tblEmail] ([emlId],[empId],[emlAddress]) VALUES (9,23,N'dwilliams@sae.org');
GO
I am hoping this is something really easy that I missed. Is the Left Outer Join not the correct way to go about this? Or is the it the right way but I'm just doing butt-backwards and wrong-side-up? Any help/suggestions/explanations is very much appreciated.
Thank you.
** edited for a typo