I am trying to create a relationship table which stores the relationship between two records in the primary table.The relationship that i am trying to represent is like Cartesian relationship. So if code A is related to code B and C then Code B is related to A and C and Code C is related to B and A . I would really appreciate if someone can suggest best way to implement as this will effect the update and the insert query. Below is the table structure
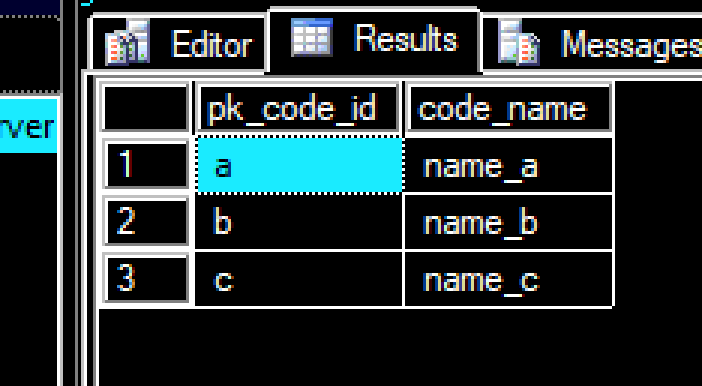
Table Codes
pk_code_id ,code_name
a, name_a
b, name_b
c, name_c
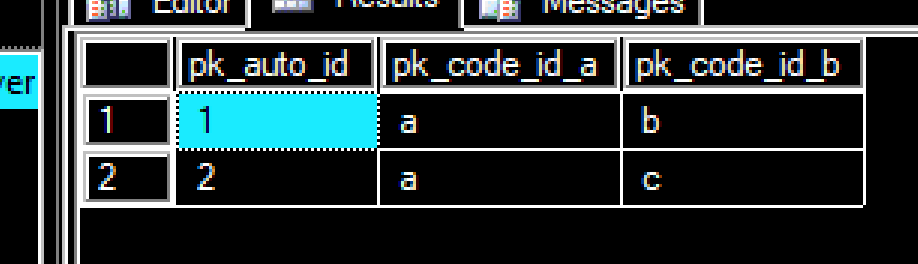
Table Codes_Link
pk_auto_id pk_code_id_a pk_code_id_b
1 a b
2 a c
3 b a
4 b c
5 c a
6 c b
I would really appreciate how best to tackle this.
Many Thanks,
Teju
Thank you Mike. I have listed the sample data in my question earlier. To further explain what i would like to achieve is as below
The Codes table is the main table which contains the details about all the codes and the codes_link table is relationship table which shows the linking between the codes if there is any in the Codes table as to what are the codes related to . So for example if code a is related to code b and code b is in turn related to code a. I have a display page which i query to show all the related codes for say for example code A. so my query will be a simple select statement
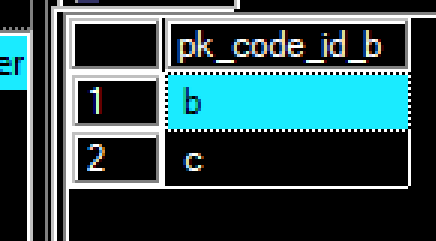
**select pk_code_id_b from Codes_link where pk_code_id_a="A"**
according to the sample data above for A it would show me b and c
I could use inner join with Codes here if i wanted to get some more details of code A from the Codes table.
The trouble would be to be insert data . In order to insert the relationship for B the values would be b to c and b to a . If there are more codes linked to B there would be more than 2 set of insert values.
insert into (pk_code_id_a,pk_code_id_b) values(a,b),(b,a)
But the real problem would be when i update the data , i will have to update all the related codes .
For both the insert and updates i cannot rely on users that they will insert/update data for all the Codes individually by going into every single Code record and update the related codes. I will have to come up with the insert statement which inserts all the related codes through one insert query as stated in the example above rather than going in the individual record and inserting .
Like wise for the update say for e.g. if code a's relationship gets changed to e then the record a would be updated to from a to b TO a to e and the (b,a) would be deleted and a new record would be inserted as e(e,a)
I need suggestions to implement this structure and in a optimised way. If i try to implement the way i have explained there will lot of duplicates in the relationship table.
I have tried to explain the scenario as much as possible.
one insert query
lot of duplicates in the relationship table.
**
solution ....
**
what you can do is with where clause
i think ..
> update codelinks
> set pk_code_id_b = 'e'
> where pk_code_id_a = 'a'
Here are all the SQL's I used
all SQLs
use tempdb
go
drop table Codes
go
create table codes
(
pk_code_id varchar(1),
code_name varchar(10)
)
go
insert into codes select 'a', 'name_a'
insert into codes select 'b', 'name_b'
insert into codes select 'c', 'name_c'
go
select * from codes
go
select a.*,b.* from codelinks a join codes b on a.pk_code_id_a = b.pk_code_id
where pk_code_id_a='a'
drop table codelinks
go
create table codelinks
(
pk_auto_id int identity(1,1),
pk_code_id_a varchar(1),
pk_code_id_b varchar(1)
)
go
drop table codelinks
go
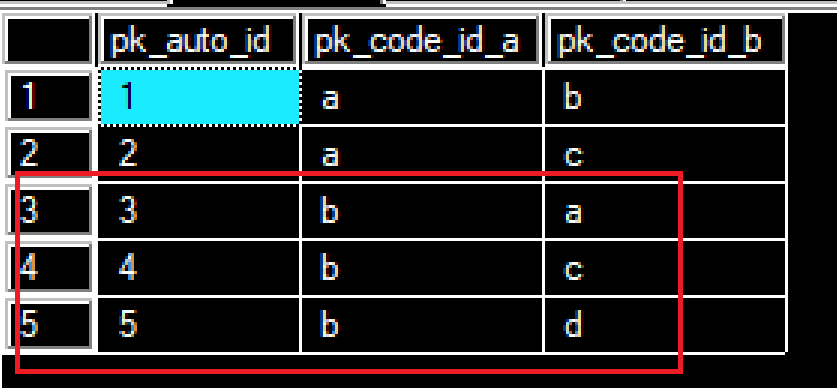
insert into codelinks select 'a', 'b'
insert into codelinks select 'a', 'c'
go
insert into codelinks(pk_code_id_a,pk_code_id_b) select 'b','a'
go
insert into codelinks(pk_code_id_a,pk_code_id_b) select 'b','c'
go
insert into codelinks(pk_code_id_a,pk_code_id_b) select 'b','d'
go
select * from codelinks
go