Sorry to bother you again experts,
I have been struggling with this now for a couple of days.
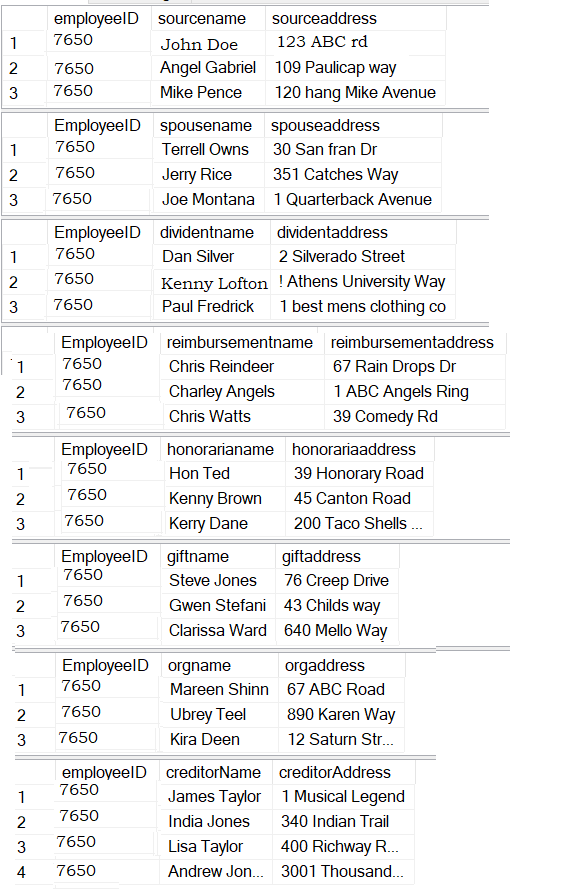
We have a total of 10 tables.
However, the one table that relates to all other tables is the Employees table and it relates to the other 9 tables by employeeID.
More importantly, there is a one to many relationship between the Employees table and the other tables except the dateDetails table where the relationship is one to one.
In other words, with the exception of the dateDetails table, where the relationship between it and the Employees table is one to one, there exists one to many relationship between Employees table and the rest of the tables.
I thought the query below would work:
SELECT DISTINCT e.employeeID,IsNULL(s.sourcename,'NA') sourcename, IsNULL(s.sourceaddress,'NA') sourceaddress,
IsNULL(sp.spousename,'NA') spousename, IsNULL(sp.spouseaddress,'NA') spouseaddress,
IsNULL(dv.dividentName,'NA') dividentName, IsNULL(dv.dividentAddress,'NA') dividentAddress,
IsNULL(r.reimbursementName,'NA') reimbursementName, IsNULL(r.reimbursementAddress,'NA') reimbursementAddress,
IsNULL(h.HonorariaName,'NA') HonorariaName, IsNULL(h.HonorariaAddress,'NA') HonorariaAddress,
IsNULL(g.giftName,'NA') giftName, IsNULL(g.giftAddress,'NA') giftAddress,
IsNULL(o.orgName,'NA') orgName, IsNULL(o.orgAddress,'NA') orgAddress,
IsNULL(cr.creditorName,'NA') creditorName, IsNULL(cr.creditorAddress, 'NA') creditorAddress
From Employees e
INNER JOIN SourceDetails s ON e.EmployeeID = s.EmployeeID
INNER Join SpouseDetails sp ON e.EmployeeID = sp.employeeID
INNER JOIN org o ON e.employeeID = o.employeeID
INNER Join DividentDetails dv ON e.EmployeeID = dv.EmployeeID
INNER JOIN ReimbursementDetails r ON e.EmployeeID = r.employeeID
INNER Join Honoraria h ON e.EmployeeID = h .EmployeeID
INNER JOIN GiftDetails g ON e.EmployeeID = g.employeeID
INNER Join dateDetails d ON e.EmployeeID = d.employeeID
INNER JOIN creditorDetails cr ON e.employeeID = cr.employeeID
WHERE cast(CONVERT(NCHAR(8),d.dateCreated,112) AS int) >= 20240125 and cast(CONVERT(NCHAR(8),d.dateCreated,112) AS int) < 20240531 and e.employeeID = 7650
GROUP BY dv.dividentname,h.HonorariaName,g.giftName,o.orgName,o.orgAddress,g.giftAddress,h.HonorariaAddress,r.reimbursementName,r.reimbursementAddress, dv.dividentAddress,e.employeeID,sp.spousename,sp.spouseaddress,s.sourcename, s.sourceaddress,cr.creditorName, cr.creditorAddress
```
I tried using DISTINCT. I also tried GROUP BY but the query keeps displaying many duplicate records.
What I posted is the actual query we are using.
Could you experts help figure out what I am doing wrong please?
Many thanks in advance