Hello,
Problem Statement:
I am trying create an query (Redshift) that will count the number of times each value appears in a column that contains comma separated values.
Details:
- The possible values in the CSV column are predefined.
- There are 14 possible values, I know these without needing to refer to the data
- Each of the 14 values can only appear in the CSV column at most once
- Each record has at least one of the 14 values in the CSV column, but could contain many (up to 14).
I tried adding tally/counter columns to my view that would record: 1 (CSV column has value) or 0 (CSV column doesn't have value)
case when [column] like '%value1%' then 1 else 0 as value_1,
case when [column] like '%value2%' then 1 else 0 as value_2,
etc.
This worked in the sense that now I have columns that indicate how many true or false whether each value is in the CSV column, however I'm struggling to summarize these tally columns in a way that gives me a count for each distinct value. Any ideas? (or maybe I'm going about this all wrong?)
as an example, the column below is represents my CSV column for a veterinarian table. the column 'pets' represent the type of pet each vet clinic works with.
pets
cat, fish, dog
cat, dog
dog
dog, bird, fish
fish, rat, cat
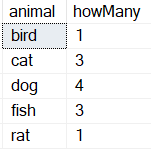
I need to produce a count of vet clinics that will see each pet type.
Desired output
bird | 1
cat | 3
dog | 4
fish | 3
rat | 1
Thank you in advance.
Welcome. This is a forum for Microsoft SQL Server. That said maybe you should look at https://docs.aws.amazon.com/redshift/latest/dg/SPLIT_PART.html
in sql, one of the many possible ways
if OBJECT_ID('tempdb..#pets') is not null
drop table #pets
create table #pets(mishmash nvarchar(150))
insert into #pets
select 'cat, fish, dog' union
select 'cat, dog' union
select 'dog' union
select 'dog, bird, fish' union
select 'fish, rat, cat'
select rtrim(ltrim(mm.value)), count(1)
from #pets p
cross apply string_split(mishmash, ',') mm
group by rtrim(ltrim(mm.value))
Thank you for the suggestion and for the clarification. I wasn't able to get the cross apply / string split to work with redshift, but I was able to make progress using a different strategy.
I am now able to get a sum for each pet type however the sum values each appear in their own column (i need them to have them transposed -- columns <-> rows). I tried using the UNPIVOT function but it doesn't seem to be compatible with Redshift. Any other ideas? (I will post the question on a Redshift specific forum if not, just wanted to check in case there was something obvious I could do here)
Note that categories are static, these 14 will never change or have new values added.
this is my query so far:
SELECT
count(case when vet.pets like '%dog%' THEN 1 ELSE NULL END) AS dog
, count(case when vet.pets like '%cat%' THEN 1 ELSE NULL END) as cat
, count(case when vet.pets like '%rat%' THEN 1 ELSE NULL END) as rat
, count(case when vet.pets like '%bird%' THEN 1 ELSE NULL END) as bird
, count(case when vet.pets like '%fish%' THEN 1 ELSE NULL END) as fish
, count(case when vet.pets like '%hamster%' THEN 1 ELSE NULL END) as hamster
, count(case when vet.pets like '%ferret%' THEN 1 ELSE NULL END) as ferret
, count(case when vet.pets like '%horse%' THEN 1 ELSE NULL END) as horse
, count(case when vet.pets like '%zebra%' THEN 1 ELSE NULL END) as zebra
, count(case when vet.pets like '%bear%' THEN 1 ELSE NULL END) as bear
, count(case when vet.pets like '%alligator%' THEN 1 ELSE NULL END) as alligator
, count(case when vet.pets like '%sugar_glider%' THEN 1 ELSE NULL END) as sugar_glider
, count(case when vet.pets like '%tiger%' THEN 1 ELSE NULL END) as tiger
, count(case when vet.pets like '%rock%' THEN 1 ELSE NULL END) as rock
FROM vet
This produces:
dog | cat | rat | bird | fish | hamster | ferret | horse | zebra | bear | alligator | sugar_glider | tiger | rock
3 | 5 | 2 | 6 | 8 | 1 | 8 | 5 | 1 | 3 | 2 | 2 | 4 | 2
I need it in the format:
dog | 3
cat | 5
rat | 2
bird | 6
fish | 8
hamster | 1
ferret | 8
horse | 5
zebra | 1
bear | 3
alligator | 2
sugar_glider | 2
tiger | 4
rock | 2
if tomorrow there is a new animal discovered your approach will not work, it is not dynamic. data is not static. I think you should post in a redshift forum
I understand. The actual query does not have to do with Animals. This is just a sample. In this case the data is static and there will never be new values added to it. I will post to a redshift forum for additional guidance.
Thank you!
@yosiasz
AWS RedShift uses a subset of Postgre behind the scenes. Of course, it's missing a lot of the big pieces because RedShift is designed for an entirely different purpose than what most people are accustomed to. This is NOT a normal RDBMS Engine.
https://docs.aws.amazon.com/redshift/latest/dg/c_redshift-and-postgres-sql.html
2 Likes
hi
you can do it like .. this
SELECT
count(case when vet.pets like '%dog%' THEN 1 ELSE NULL END) AS dog
FROM vet
union all
select count(case when vet.pets like '%cat%' THEN 1 ELSE NULL END) as cat
FROM vet
union all
select count(case when vet.pets like '%rat%' THEN 1 ELSE NULL END) as rat
from vet
union all
......
....
....
1 Like
yes! That did it. Thank you Harishgg1. just a slight modification: i added a column to call out which animal instance was being counted:
SELECT
'dog' AS animal,
count(case when vet.pets like '%dog%' THEN 1 ELSE NULL END) AS count
FROM vet
Union all
SELECT etc....
Thank you for the suggestion! 