How to show years starting from 2000 to 2025 using CTE?
This is a interview question. Thanks in advance.
with cte as (
select [year] from (values
(2000), (2001), (2002), ...,
(2024), (2025)) v(y)
)
select [year] from cte;Tally tables are great for all such iterative tasks, therefore I'd use one for this, as below. Want to change to years 2000 - 2050? Change just the WHERE clause and you're done!
;WITH
cteTally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cteTally100 AS (
SELECT ROW_NUMBER() OVER(ORDER BY c1.number) - 1 AS number
FROM cteTally10 c1
CROSS JOIN cteTally10 c2
)
SELECT 2000 + t.number
FROM cteTally100 t
WHERE t.number BETWEEN 0 AND 25Here's another efficient approach
;WITH Nums ( zero, num )
AS ( SELECT 0 ,
ROW_NUMBER() OVER ( ORDER BY object_id )
FROM sys.columns
)
SELECT 2000 [Year]
UNION
SELECT 2000 + num
FROM Nums
WHERE num BETWEEN 1 AND 25;
Original Incorrect Response
Careful now... It's actually NOT an efficient approach. Please see the following article for proof. Even such small row counts use way to many resources for what is being done. Don't use rCTEs that increment
I've hidden my original response on this because I misread the code above. At quick glance, I saw the UNION and called it an inefficient rCTE. It's actually good code that used sys.columns as a "pseudo-cursor" and the UNION is part of a trick to avoid having to subtract 1 FROM RowNum. I even use that same trick in the production version of the fnTally function I wrote and I missed it here.
My apologies for the confusion,
http://www.sqlservercentral.com/articles/T-SQL/74118/
Hello everybody..Thanks for the help and replies..
Hello ScottPletcher, it will be very helpful, if you please explain the code.
One of my friend suggested something like this. Please comment on the code below, if its efficient or not.
with yearlist as
(
select 2000 as year
union all
select yl.year + 1 as year
from yearlist yl
where yl.year + 1 <= 2025
)
select year from yearlist order by year asc;See Jeff's post, above. Recursive CTEs are not an efficient way to do this sort of thing. Scott's tally-table based solution is much better (I admit mine was facetious!) Google Tally tables in sql server for tons more examples and explanations
An even more efficient rendition of Scott's code is as follows:
WITH
cteTally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cteTally100 AS (
SELECT TOP (25) ROW_NUMBER() OVER(ORDER BY c1.number) - 1 AS number
FROM cteTally10 c1
CROSS JOIN cteTally10 c2
)
SELECT 2000 + t.number
FROM cteTally100 t
--WHERE t.number BETWEEN 0 AND 25 --Moved from here to the TOP () in cteTally100
;
What this does is the cteTally10 generates 10 up to 10 rows. What they contain is of little consequence. We only care about the "presence of rows".
The cteTally100 uses the up to 10 rows from cteTally100 in a CROSS JOIN on itself generating up to 100 rows. TOP() limits the number of rows from both cteTally10 and cteTally100 (Scott's had to generate all 100 rows to get the "num" as a criteria... the TOP() mode I used does not).
Within cteTally100, the presence of rows are converted to actual numbers using ROW_NUMBER(). In this case, TOP(25) limits it to only 25 and the 25 could be a variable. Because of the "-1" in the ROW_NUMBER() formula, the numbers 0 through 24 are generated by cteTally100 in this case.
The outer query simply adds "2000" (the first desired year) to the values 0 though 24 to produce the years of 2000 thru 2024.
The original idea of using such cCTEs (my term for them... stands for Cascading CTEs as opposed to the slothful rCTEs (Recursive CTEs) was from Itzik Ben Gan.
There are a huge number of uses for such Tally-Table-like structures. They are frequently referred to either as a "Tally" or "Numbers" table and, as Gerald (@gbritto) posted above, are a simple search away. These structures will change your way of thinking about SQL Server and once you start thinking in columns instead of rows, your code will become a whole lot faster and a whole lot less resource intensive.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
GO
DECLARE @time DATETIME2= SYSDATETIME();
WITH cteTally10
AS ( SELECT *
FROM ( VALUES ( 0), ( 0), ( 0), ( 0), ( 0), ( 0), ( 0),
( 0), ( 0), ( 0) ) AS numbers ( number )
),
cteTally100
AS ( SELECT ROW_NUMBER() OVER ( ORDER BY c1.number ) - 1 AS [Year]
FROM cteTally10 c1
CROSS JOIN cteTally10 c2
)
SELECT 2000 + t.[Year]
FROM cteTally100 t
WHERE t.[Year] BETWEEN 0 AND 25;
SELECT @time = SYSDATETIME();
SELECT DATEDIFF(NANOSECOND, @time, SYSDATETIME()) TallyExecutionNanoSeconds;
SET @time = SYSDATETIME();
WITH Nums ( zero, num )
AS ( SELECT 0 ,
ROW_NUMBER() OVER ( ORDER BY column_id )
FROM sys.columns
)
SELECT Nums.num
FROM Nums
WHERE Nums.num BETWEEN 2000 AND 2025;
SELECT DATEDIFF(NANOSECOND, @time, SYSDATETIME()) RecursiveCTEExecutionNanoSeconds;
SET @time = SYSDATETIME();
SELECT
number
FROM master.dbo.spt_values
WHERE number BETWEEN 2000 AND 2025;
SELECT DATEDIFF(NANOSECOND, @time, SYSDATETIME()) Spt_valuesExecutionNanoSeconds;
SET @time = SYSDATETIME();
SET NOCOUNT ON;
DECLARE @num INT = 2000;
DECLARE @tbl TABLE (num int);
WHILE @num < 2026
BEGIN
INSERT @tbl
( num )
VALUES ( @num );
SET @num += 1;
END
SELECT
num [Year]
FROM
@tbl;
SELECT DATEDIFF(NANOSECOND, @time, SYSDATETIME()) WhileLoopExecutionNanoSeconds;
SET @time = SYSDATETIME();
WITH
cteTally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cteTally100 AS (
SELECT TOP (25) ROW_NUMBER() OVER(ORDER BY c1.number) - 1 AS number
FROM cteTally10 c1
CROSS JOIN cteTally10 c2
)
SELECT 2000 + t.number
FROM cteTally100 t;
SELECT DATEDIFF(NANOSECOND, @time, SYSDATETIME()) Tally2ExecutionNanoSeconds;DBCC execution completed. If DBCC printed error messages, contact your system administrator.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
TallyExecutionNanoSeconds
0
num
RecursiveCTEExecutionNanoSeconds
31250900
number
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
Spt_valuesExecutionNanoSeconds
31257500
Year
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
WhileLoopExecutionNanoSeconds
0
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
Tally2ExecutionNanoSeconds
0
Hey Jeff, I was doing some experimenting the other day and found that
ROW_NUMBER() OVER(ORDER BY <some column>)
often results in a sort in the plan but
ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
doesn't
Can you confirm?
PS of course this is only relevant when you don't care about the order, as here, IIUC
1 Like
Hi Gerald,
The only time I've seen an ROW_NUMBER() OVER(ORDER BY ) result in a SORT operator in the execution plan is when is from a physical column rather than a calculated column of identical values. The SELECT NULL version does add an extra COMPUTE SCALAR as compared to adding the "N" column from the cCTE.
--------------------------------------------------------------------------------------------------------------
GO
--===== Using ORDER BY (SELECT NULL)
DECLARE @MaxN BIGINT = 1000000, @BitBucket BIGINT
;
WITH
E1(N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1) --10E1 or 10 rows
, E4(N) AS (SELECT 1 FROM E1 a, E1 b, E1 c, E1 d) --10E4 or 10 Thousand rows
,E12(N) AS (SELECT 1 FROM E4 a, E4 b, E4 c) --10E12 or 1 Trillion rows
SELECT TOP(@MaxN) @BitBucket = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E12 -- Values from 1 to @MaxN
;
GO 5
--------------------------------------------------------------------------------------------------------------
GO
--===== Using ORDER BY N
DECLARE @MaxN BIGINT = 1000000, @BitBucket BIGINT
;
WITH
E1(N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1) --10E1 or 10 rows
, E4(N) AS (SELECT 1 FROM E1 a, E1 b, E1 c, E1 d) --10E4 or 10 Thousand rows
,E12(N) AS (SELECT 1 FROM E4 a, E4 b, E4 c) --10E12 or 1 Trillion rows
SELECT TOP(@MaxN) @BitBucket = ROW_NUMBER() OVER (ORDER BY N) FROM E12 -- Values from 1 to @MaxN
;
GO 5
With the execution plan turned off and @BitBucket removing any disk or display play from the equation, here's what I get from SQL Server Profiler (still my favorite). Over a million rows, the SELECT NULL method is about 2ms slower because of the extra COMPUTE SCALAR operation. As they say, YMMV.
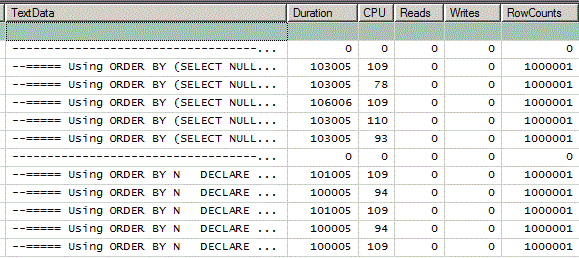
I'm not finding the word "UNION" anywhere in the test code that you posted which also means that no rCTE was tested in it. It also means that you've changed your original code.
It also means that I'm an idiot and I owe you an apology. I saw the UNION in the first code you posted and mistook it for a recursive CTE rather than using sys.columns as a simple row source, which I frequently do myself. What's really bad (can't post without coffee, apparently) is that I use the same great trick that you used for avoiding the need to subtract 1 from the RowNumber in my fnTally function.
Is it efficient to use this piece of code in stored procedures, especially in stored procedures which are running slow ?
No and that's not why @jotorre_riversidedpss.org included it. It just a part of the test setup so that if you change the code under test, that it does NOT used a cached execution plan that's possibly "only" good enough. Those two DBCC commands should never actually be made a part of a stored procedure unless it's a part of some "emergency hail-Mary" code or "after the nightly runs are over" scheduled code where the specific need to clear procedure cache to overcome a parameter sniffing problem server wide has been identified correctly.
Good job I didn't reply to the original (although WHY am I doing so now?)
In that situation I would always have avoided the UNION and done hte "subtract 1 from the RowNumber in my fnTally" instead
![]()
Absolutely not (well NOT on a production server), might be OK on a Test Server as an ... ermmm ... test ![]() Jeff's edge condition for "After the overnight run" might be acceptable - I would still be loath to do that here.
Jeff's edge condition for "After the overnight run" might be acceptable - I would still be loath to do that here.
Might you be thinking of RECOMPILE ?
Too many bear popsicles with the dust bunnies.