@harishgg1,
Thank you very much for posting your code and especially the test data setup in a readily consumable fashion. That would be the way to get answers much more quickly in the future if the OP took the time to post such a thing in the original post.
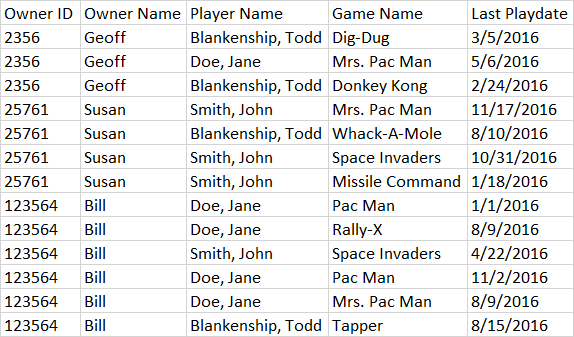
On that note, here's a bit of a simplification instead of using individual INSERTs. It also helps folks more clearly visualize the data in their mind without having to do a separate select to see the content of the table while they're developing a coded, tested answer for the OP and others.
--===== If the test table already exists, drop it to make reruns in SSMS easier
IF Object_id('tempdb.dbo.#abc', 'U') IS NOT NULL
DROP TABLE #abc
;
GO
--===== Create the test table
CREATE TABLE #abc
(
ownerid INT NOT NULL
,ownername VARCHAR(100) NOT NULL
,playername VARCHAR(100) NOT NULL
,gamename VARCHAR(100) NOT NULL
,lastplaydate DATETIME NOT NULL
)
;
--===== Populate the test table.
-- I still like SELECT/UNION ALL because you don't have to worry
-- about a gazillion parenthesis nor the limits of VALUES.
INSERT INTO #abc
(ownerid, ownername, playername, gamename, lastplaydate)
SELECT 2356 , 'Geoff', 'Todd', 'Dig-Dug' , '3/5/2016' UNION ALL
SELECT 2356 , 'Geoff', 'Jane', 'M Pac-Man', '5/6/2016' UNION ALL
SELECT 2356 , 'Geoff', 'Todd', 'Kong' , '2/24/2016' UNION ALL
SELECT 25761 , 'Susan', 'John', 'M Pac-Man', '11/17/2016' UNION ALL
SELECT 25761 , 'Susan', 'Todd', 'Mole' , '8/10/2016' UNION ALL
SELECT 25761 , 'Susan', 'John', 'Space' , '10/31/2016' UNION ALL
SELECT 25761 , 'Susan', 'John', 'Missile' , '1/18/2016' UNION ALL
SELECT 123564, 'Bill' , 'Jane', 'Pac-Man' , '1/1/2016' UNION ALL
SELECT 123564, 'Bill' , 'Jane', 'Rally' , '8/9/2016' UNION ALL
SELECT 123564, 'Bill' , 'John', 'Space' , '4/22/2016' UNION ALL
SELECT 123564, 'Bill' , 'Jane', 'Pac-Man' , '11/2/2016' UNION ALL
SELECT 123564, 'Bill' , 'Jane', 'M Pac-Man', '8/9/2016' UNION ALL
SELECT 123564, 'Bill' , 'Todd', 'Tapper' , '8/15/2016'
;
GO
Here's a copy of the code that you posted. I've added SET STATISTICS to the code so we can see what plays out behind the scenes.
SET STATISTICS TIME,IO ON
;
SELECT DISTINCT sub.playername,
x.gamename,
Count(sub.gamename),
Count(DISTINCT sub.gamename)
FROM #abc sub
OUTER apply (SELECT CASE Row_number() OVER (ORDER BY stu.gamename) WHEN 1
THEN
'' ELSE ', '
END +
stu.gamename
FROM (SELECT DISTINCT playername,
gamename
FROM #abc) stu
WHERE stu.playername = sub.playername
ORDER BY stu.playername
FOR xml path('')) x (gamename)
--WHERE sub.PlayerName = 'Jane'
GROUP BY sub.playername,
x.gamename
;
SET STATISTICS TIME,IO OFF
;
If we look at the statistical results, we find that it's fairly well READ intensive (1 Logical READ = 8,192 bytes of Memory I/O) and a bit complicated. It also does NOT de-entitize special XML characters such as the "&", which will eventually become a problem (which I've not demonstrated here).
(3 row(s) affected)
Table 'Worktable'.
Scan count 25, logical reads 86, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table '#abc________________________________________________________________________________________________________________000000000028'.
Scan count 4, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Using the STUFF function to take out the leading ", " in the result allows us to simplify the code quite a bit and the simplification also cuts way down on the number of the Logical Reads. Here's the code...
SET STATISTICS TIME,IO ON
;
SELECT t1.PlayerName
,GamesPlayed = STUFF( --Removes the leading ", "
( --=== Does the correlated concatenation with de-entitization
SELECT ', ' + t2.gamename
FROM #abc t2
WHERE t2.playername = t1.playername
ORDER BY t2.gamename
FOR XML PATH(''),TYPE
).value('(./text())[1]','varchar(max)')
,1,2,'') --Removes the leading ", "
,[Total Games Played] = COUNT(*)
,[Unique Games Played] = COUNT(DISTINCT t1.GameName)
FROM #abc t1
GROUP BY t1.PlayerName
;
SET STATISTICS TIME,IO OFF
;
... and here's the statistical output...
(3 row(s) affected)
Table '#abc________________________________________________________________________________________________________________000000000028'.
Scan count 5, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'.
Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
... and that's down from 90 total Logical Reads down to just 5.
I've not tested this particular code for performance on larger data sets but I believe you'll find that there is a worthwhile difference on larger data sets.
Now, if we could just get @elzool (the OP) to post his/her code solution they came up with, we might be able to help a bit there, as well.