Hi.
I have this view that i call
SELECT CAST(CONVERT(VARCHAR, CASE WHEN Datepart(hh, CollectedDate) < 6 THEN DATEADD(d, -1, CollectedDate) ELSE CollectedDate END, 112) AS DATETIME) AS CollectedDate,
CollectedUserCode, ISNULL(User_strLastName,'') + ' ' + ISNULL(User_strFirstName,'') AS CollectedUserName,
CollectedWorkStationCode, tblWorkstation.Workstation_strName AS CollectedWorkStationName,
ItemCode, ItemDescription,
SUM(Quantity) AS Quantity,
SUM(GrossValue) AS GrossValue,
SUM(VATValue) AS VATValue,
SUM(NetValue) AS NetValue
FROM [dbo].[ZZ_vwConsCollectedDTL]
LEFT OUTER JOIN dbo.tblWorkstation WITH (NOLOCK) ON tblWorkstation.Workstation_strCode = CollectedWorkStationCode
LEFT OUTER JOIN dbo.tblUser WITH (NOLOCK) ON tblUser.User_intUserNo = CollectedUserCode
WHERE CAST(CONVERT(VARCHAR, CASE WHEN Datepart(hh, CollectedDate) < 6 THEN DATEADD(d, -1, CollectedDate) ELSE CollectedDate END, 112) AS DATETIME) between '20170101' and '20170102'
GROUP BY CAST(CONVERT(VARCHAR, CASE WHEN Datepart(hh, CollectedDate) < 6 THEN DATEADD(d, -1, CollectedDate) ELSE CollectedDate END, 112) AS DATETIME),
CollectedUserCode,
ISNULL(User_strLastName,'') + ' ' + ISNULL(User_strFirstName,''),
CollectedWorkStationCode, tblWorkstation.Workstation_strName,
ItemCode, ItemDescriptionThe view itself is as:
CREATE VIEW [dbo].[ZZ_vwConsCollectedDTL] AS
SELECT CASE WHEN ISNULL(TransI_decActualNoOfItems,0) < 0 THEN TransI_dtmRealTransTime --Refund
ELSE CASE WHEN tblBooking_Header.BookingH_intNextBookingNo IS NULL THEN TransI_dtmRealTransTime ELSE TransI_dtmDateCollected END
END AS CollectedDate,
CASE WHEN ISNULL(TransI_decActualNoOfItems,0) < 0 THEN User_intUserNo --Refund
ELSE CASE WHEN tblBooking_Header.BookingH_intNextBookingNo IS NULL THEN User_intUserNo ELSE ZZ_tblTrans_Inventory_EXT.TransI_intPickupUser END
END AS CollectedUserCode,
CASE WHEN ISNULL(TransI_decActualNoOfItems,0) < 0 THEN Workstation_strCode --Refund
ELSE CASE WHEN tblBooking_Header.BookingH_intNextBookingNo IS NULL THEN Workstation_strCode ELSE ZZ_tblTrans_Inventory_EXT.TransI_strPickupWorkstn END
END AS CollectedWorkStationCode,
tblItem.HOPK AS ItemCode,
tblItem.Item_strItemDescription AS ItemDescription,
ISNULL(TransI_decActualNoOfItems,0) AS Quantity,
ISNULL(TransI_curValueEach,0) AS GrossUP,
CAST(ROUND(ISNULL(TransI_curValueEach,0)*ISNULL(TransI_decActualNoOfItems,0),2) AS MONEY) AS GrossValue,
CAST(ROUND((ISNULL(TransI_curSTaxEach,0)+
ISNULL(TransI_curSTaxEach2,0)+
ISNULL(TransI_curSTaxEach3,0)+
ISNULL(TransI_curSTaxEach4,0))*ISNULL(TransI_decActualNoOfItems,0),2) AS MONEY) AS VATValue,
--NET = GROSS - TAX
CAST(ROUND(ISNULL(TransI_curValueEach,0)*ISNULL(TransI_decActualNoOfItems,0),2)-
(ROUND((ISNULL(TransI_curSTaxEach,0)+
ISNULL(TransI_curSTaxEach2,0)+
ISNULL(TransI_curSTaxEach3,0)+
ISNULL(TransI_curSTaxEach4,0))*ISNULL(TransI_decActualNoOfItems,0),2)) AS MONEY) AS NetValue
FROM VISTA.dbo.tblTrans_Inventory WITH (NOLOCK)
INNER JOIN VISTA.dbo.tblItem WITH (NOLOCK)
ON tblItem.Item_strItemId = tblTrans_Inventory.Item_strItemId
LEFT OUTER JOIN VISTA.dbo.ZZ_tblTrans_Inventory_EXT WITH (NOLOCK)
ON tblTrans_Inventory.TransI_lgnNumber = ZZ_tblTrans_Inventory_EXT.TransI_lgnNumber
AND tblTrans_Inventory.TransI_intSequence = ZZ_tblTrans_Inventory_EXT.TransI_intSequence
LEFT JOIN VISTA.DBO.tblBooking_Header WITH (NOLOCK) ON tblBooking_Header.TransC_lgnNumber = tblTrans_Inventory.TransI_lgnNumber
WHERE tblItem.Item_strBookingFee <> 'Y'
AND TransI_dtmDateCollected < '9999-01-01 00:00:00.000'It takes a very log time and i am trying to do some optimization.
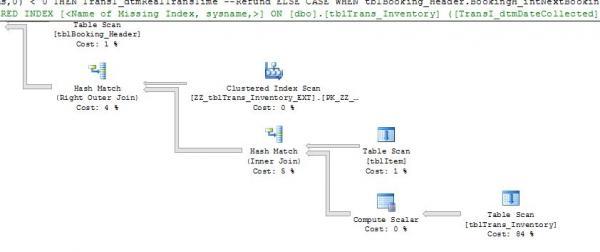
The execution plan , the main issue seems to be the tblTrans_Inventory

If you can see on the missing index point at TransI_dtmDateCollected but the problem is that TransI_dtmDateCollected is already included in 2 non clustered indexes

and

So any thoughts?
Thanks.