Hi everybody,
I have table with hundreds of rows such as the following example
Node-1 Node-2 ID
Strt1 Bg2 567
Bf1 Bg2 567
Hr Bf1 567
Strt2 Al3 788
Al3 Bo67 788
The output should find the last node per group ID. The starting node on each ID is known (in the example str1 and strt2).
The ouput should be something like that:
Start node Last-node ID
Strt1 Hr 567
Strt2 Bo67 788
NB: The number of rows in the inputs per ID is variable.
Please advise how this can be achieved.
Please provide your data with clean ddl and dml?
Hi I m not sure if got well ur question, but thr original table conatins many rows that can t display all so i just put a part of it:
Input
Node-1 | Node-2 | ID
Strt1 | Bg2 | 567
Bf1 | Bg2 | 567
Hr | Bf1 | 567
Strt2 | Al3 | 788
Al3 | Bo67 | 788
Output
Start-node | Last-node | ID
Strt1 | Hr | 567
Strt2 | Bo67 | 788
hi
you can add row number for each ID .. then select max row number
only thing i am worried about is the order by clause .. whether its reliable !!!
 hope this helps
hope this helps
please click arrow to the left for Create Data
----------------------
-- create table
create table temp
(
[Node-1] varchar(10), [Node-2] varchar(10) , ID int
)
go
---------------------------
-- insert table
insert into temp select 'Strt1','Bg2', 567
insert into temp select 'Bf1','Bg2',567
insert into temp select 'Hr','Bf1 ',567
insert into temp select 'Strt2','Al3', 788
insert into temp select 'Al3','Bo67 ', 788
go
-- SQL
; with cte as
(
select ROW_NUMBER() over ( partition by ID order by (select null) desc ) as rn , * from temp
)
select 'SQL Output', * from cte where rn = 1
go
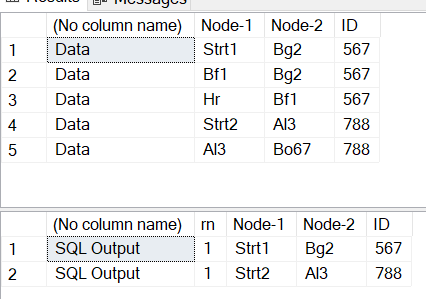
Hi harish, thank u for ur feedback!!
The script returns the starting node and the next node, however the output table shall be the starting node and last node. For example for an ID X we have NodeA - NodeB and NodeB-NodeC and NodeK-NodeC then out shall be for IDX NodeA-NodeK
hi
hope this helps
; with cte as
(
select ROW_NUMBER() over ( partition by ID order by (select null) desc ) as rn , * from temp
) ,cte_min_max as
(
select min(rn) as minrn,max(rn) as maxrn,id from cte group by id
)
select a.[Node-1]+'-'+c.[Node-2],b.ID from cte a join cte_min_max b on a.ID = b.ID and a.rn = b.minrn join cte c on c.rn = b.maxrn and c.ID = b.ID
go
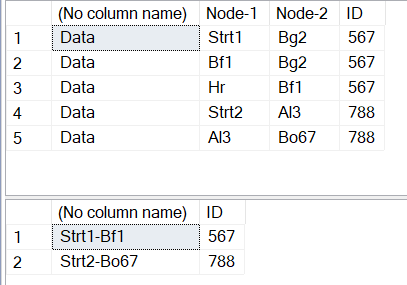
Hi Harish, thank you so much for the solution. in regards to the first and last node, they are not always at the min and max row. so you could have NodeB-NodeC and NodeK-NodeC and NodeA - NodeB and thus the results i think will not match Node A- Node K. one more Information that i related before is that the starting node is known value (in here for example Node A). my first perception as programmer was to make a loop starting from the first node and look for the next node per line till we reach the last one but i m not sure how to apply it on SQL.
Can you explain the logic in traversing the records. How do you come up with Strt1 Hr 567 for ID 567?
Hi, so within ID 567, the starting Point is known which is Strt1 then we look for first Destination which is Bg2 and then Bg2 goes to Bf1 and then Bf1 goes to Hr, at that Level we have no more Destination node which implies that Hr is the last node and then Output for ID 567 would be Strt1 - Hr.
what data guarantees the sorting? Are we missing some other date time column?
Hi so the processing shall be per ID and the sorting using node 1 and node 2 is taking into account that starting node is always like 'strt%'
hi
if you don't mind
.. could you please put some test data for your scenario and explain ....
I am finding it tough to understand !!
thank you
Hi yes sure. here is the Input for that Scenario :
| Node 1 | Node 2 | ID |
|---|---|---|
| Herr5 | Pol2 | 344 |
| Strt7 | att3 | 344 |
| Ares3 | kbb5 | 344 |
| kb55 | att3 | 344 |
| Pol2 | Ares3 | 344 |
and the Output would be
| Node 1 | Node 2 | ID |
|---|---|---|
| Strt7 | Herr5 | 344 |
hi i tried to do this !! hope this helps ..
this only works if the data follows the same pattern .. for which i wrote SQL ..
Assumption = all will be duplicates except for Str and Final Destination Node ..
please click arrow to the left for Create Data
create table data (
Node1 varchar(100) , Node2 varchar(100) , ID int
)
go
insert into data select 'Herr5','Pol2',344
insert into data select 'Strt7','att3',344
insert into data select 'Ares3','kbb5',344
insert into data select 'kbb5','att3',344
insert into data select 'Pol2','Ares3',344
insert into data select 'Strt1','Bg2', 567
insert into data select 'Bf1','Bg2',567
insert into data select 'Hr','Bf1 ',567
insert into data select 'Strt2','Al3', 788
insert into data select 'Al3','Bo67 ', 788
go
; with cte as
(
select node1 , id from data
union all
select node2 , id from data
)
, cte_only_one as
(
select id
, node1
, count(*) as cnt
from cte
group by id,node1
having count(*) =1
)
select id
, max(case when node1 like 'str%' then node1 end)as Node1
, max(case when node1 not like 'str%' then node1 end) as Node2
from cte_only_one
group by id
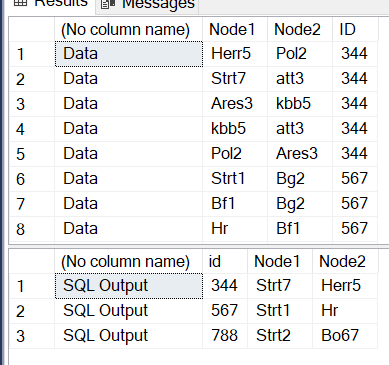
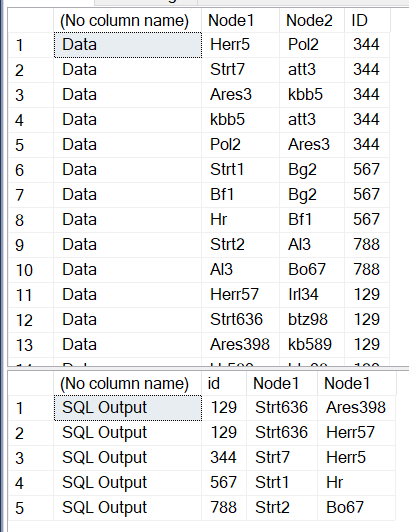
Hi Harish, very smart way of sorting it out. it does work on 80% as your assumption defintely stands!!on the 20% of the cases I have 2 more terminations but the starting Point is Always one. i took the example below :
Input:
| Node 1 | Node 2 | ID |
|---|---|---|
| Herr57 | Irl34 | 129 |
| Strt636 | btz98 | 129 |
| Ares398 | kb589 | 129 |
| kb589 | btz98 | 129 |
| Irl34 | btz98 | 129 |
Output
| Node 1 | Node 2 | ID |
|---|---|---|
| Strt7 | Herr57 | 129 |
| Strt7 | Ares398 | 129 |
hi floyd
.... data is always very complex ( there can be many many scenarios )
idea is the same ..
modified my sql a bit .. it will give you the output for this scenario also !!
; with cte as
(
select node1 , id from data
union all
select node2 , id from data
)
, cte_only_one as
(
select id
, node1
, count(*) as cnt
from cte
group by id,node1
having count(*) =1
)
select 'SQL Output'
, a.id
,a.Node1
,b.Node1
from
( select * from cte_only_one where Node1 like 'Str%' ) a
join
( select * from cte_only_one cte_only_one where Node1 not like 'Str%') b
on a.ID = b.ID
order by a.id
1 Like
respect! thank you so much Harish
Sorry, still confused. Starting with Node1 = STR1, Node 2 - Bg2. Then you take BG2 and look for either Node1 or Node2 = BG2 on another record? Then that finds 2 records (Str1 in Node1 and Bf1 in Node1)? So it's cyclical and will never return properly. Your explanation doesn't help unless you are crossing Nodes, then that leads to the first issue. Can you clarify with data and real logic so if someone stumbles across this thread in the future, they will understand what you are trying to do?