Hi everyone,
This table has 12 million rows.
Scan density: 91%
Logical scan fragmentation: 2%
Extent Scan fragmentation: 46 %
Average page density: 92%
All-in-all it looks pretty good but how can I reduce the Extent Scan fragmentation? Would 45 % impact performance?
Thanks
What have you tried so far?
You must be using the old DBCC command to even see that stat.
From SQL 2005 on (IIRC), you should be using:
SELECT * FROM sys.dm_db_index_physical_stats (...)
dmv rather than a DBCC command to look at table/index fragmentation.
That's exactly what i ran just after I posted. The ones that show a High frag percent (> 60)
have low fragment counts and low record counts. My sense is that this tables indexes are healthy.
We re-index every night.
@ScottPletcher I ran this:
--To Find out fragmentation level of a given database and table
--This query will give DETAILED information
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N'MyDB');
SET @object_id = OBJECT_ID(N'MyTable');
IF @object_id IS NULL
BEGIN
PRINT N'Invalid object';
END
ELSE
BEGIN
SELECT IPS.Index_type_desc,
IPS.avg_fragmentation_in_percent,
IPS.avg_fragment_size_in_pages,
IPS.avg_page_space_used_in_percent,
IPS.record_count,
IPS.ghost_record_count,
IPS.fragment_count,
IPS.avg_fragment_size_in_pages
FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , 'DETAILED') AS IPS;
END
GO
Results are:
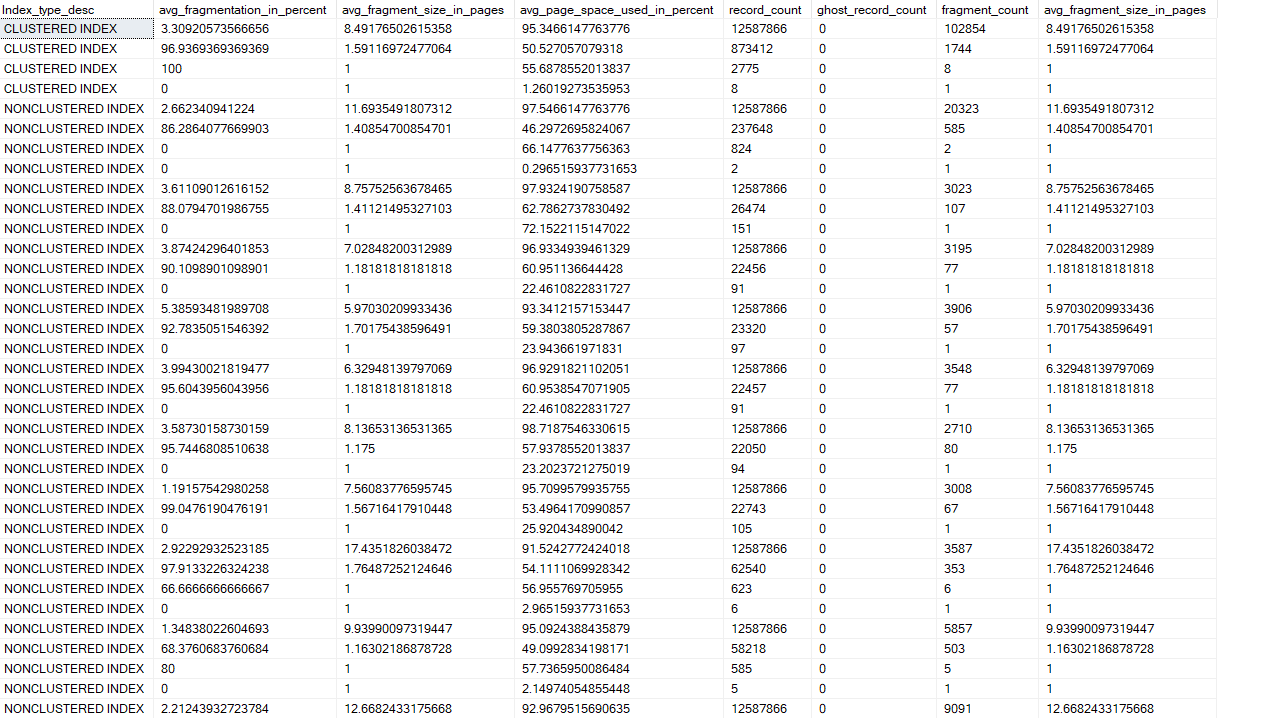
That's very likely excessive. You don't need to do that.
The first and by far the most important factor in tuning indexes is to get the best clustered index on every table. (Note that most often this is NOT on IDENTITY!!)
After that you can worry about nonclustered indexes and fragmentation.
There's no indication from what you posted which indexes are on the same tables. Without some context, the numbers are somewhat meaningless.
It's a funny thing... Extent Fragmentation (only available in DBCC SHOWCONTIG) is actually quite important when it comes to performance of Range Scans. They tried to make it a bit more understandable with that segment size thingy but it's still not as good.
What I've done with my larger Clustered Indexes to prevent such "Extent Fragmentation" is to move them to their own file and file group. If and when they need to be rebuilt, I build a new file and file group, do a CREATE INDEX WITH (DROP_EXISTING) to the new file/filegroup and then drop the old file/file group. I repeat that between a #1 and #2 file group (back and forth) when it needs to be done again. It also means that I'm not having a huge amount of unwanted free space from the rebuilds in the PRIMARY datafile or anywhere else, for that matter
You do need the freespace on the drive to do that as you would for regular rebuilds but the free-space is never locked up by one database. It can be used by other databases for similar activities.
And, I agree.... Rebuilding every night is a real waste. You need to figure out what is causing the fragmentation and fix it. And remember that rebuilding indexes is a really expensive way to update statistics. In a lot of cases, selective statistics rebuilds are all that's really necessary. As a protracted experiment, I went almost 4 years on my main production server essentially with no index maintenance (just did it about once a month on some of the larger append only indexes that needed space recovery because of the Insert/ExpAnsive Updates they were doing).
I understand that this is an option - but are you aware that this prevents you from using trace flag 2549? That trace flag can significantly improve the performance of your integrity checks - if you can guarantee that all files for that database are on separate drives.
That may or may not be an issue for you - but on larger systems it could definitely have an impact.
If you want to comprehensively reviews indexes for a table(s), I have scripts we can use to do that.
If you want to just do a quick check to say "my existing indexes are being properly rebuilt", others can help with that. I don't see much point in correctly rebuilding indexes that are wrongly chosen to begin with.
Ok. It sounds like you have some experience with that trace flag. So, how long did your CHECKDB runs use to take with it off and how long do they take now that they're on? And do you have any partitioned tables that use more than one file and each file is on a different file group?
Also, you're aware of the following for 2016 and above?
I, for one, would like to see those. I believe you posted them once before but I've unfortunately lost track of that thread.
Yes - I am aware of the improvements that were made in 2016. Prior to upgrading to 2016 a physical only integrity check of a 3TB database took nearly 14 hours. The upgrade dropped that to less than 8 hours and the trace flag reduced it to less than 3 hours.
I really wanted to see how it would fare on the 10TB+ system - but we were not able to upgrade to 2016 on that system before they migrated off the platform.
As outlined in the trace flag - not every database will see improvements using that trace flag. If you have multiple files for a database on the same drive - then it wouldn't even be an option.
I haven't seen any real number of physical db issues since going to SQL 2008 (about 12 years now).
The one or two (maybe) we did have were, luckily, for nonclustered indexes (we had to kill a very long update, which likely caused the issues). I was able to just drop and recreate the index.
Not even if they're in a separate file group?
I've seen many people say that they review the queries to tune indexes. I'd like to see how one would be able to do that. Query store plus maybe? It would take a lot of time to capture and review all those queries.
For me, it just wouldn't be realistic, since I'm responsible for tuning more than 1000 dbs (and thus 100Ks of indexes, total). Therefore, I can't imagine having to look at queries every time to tune indexes. Frankly, for the most part, I can't think of why you'd need to do that.
I do, of course, look at the mega-queries, as identified by the top I/O reports and/or our developers. And sometimes the query stats are such that I have to find the original query(ies) involved. But that's a relatively small percentage of the time.
@ScottPletcher - You mentioned the index script that you had. Any chance of you attaching that or posting it or PM'ing it to me somewhere? I saw it once before but lost track of the link you posted it at.
Not according to the documentation - must be by drive letter (but I assume that is also by mount point - but that is just an assumption).
Sorry it took me a bit to get back to this, been addressing disk space issues at work.
Next post will be the external (outside my company) version of the script. ((The internal version has additional info that might be presented such as index stats/heuristics, cardinality info, and/or statements to CREATE STATISTICS if it looks like they are needed. But that code relies on other internal code/objects that I've created.))
NOTE: From SQL 2016 on, I've found vastly less need to generate new statistics for column combinations because SQL does a much better job of determining when it can do a lookup after an index seek/scan vs having to do a full clus index scan from the start.
Btw, the @variables are listed in alpha order because, why not, it makes them easier to find when you need to.
IT IS NOT SAFE TO RUN THIS SCRIPT ON A DB WITH MANY THOUSANDS (10K+) OF INDEXES. It will require too much memory for that for many indexes.
/*capture changed system settings so that they can be reset at the end of this script*/
DECLARE @deadlock_priority smallint
DECLARE @transaction_isolation_level smallint
SELECT @deadlock_priority = deadlock_priority, @transaction_isolation_level = transaction_isolation_level
FROM sys.dm_exec_sessions
WHERE session_id = @@SPID
SET DEADLOCK_PRIORITY -8; /*"tell" SQL that if this task somehow gets into a deadlock, cancel THIS task, NOT any other one*/
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SET NOCOUNT ON;
DECLARE @filegroup_name nvarchar(128)
DECLARE @include_system_tables bit
DECLARE @list_filegroup_and_drive_summary bit
DECLARE @list_missing_indexes bit
DECLARE @list_missing_indexes_summary bit
DECLARE @list_total_size bit
DECLARE @max_compression int
DECLARE @order_by smallint /* -2=size DESC; 1=table_name ASC; 2=size ASC; */
DECLARE @table_name_pattern sysname
DECLARE @table_name_exclude_pattern sysname = '#%'
SET @list_missing_indexes = 1 --NOTE: can take some time, set to 0 if you don't want to wait.
SET @list_missing_indexes_summary = 0 /*not available unless you uncomment the code for it which requires DelimitedSplit8K function*/
SET @order_by = -2 /* -2=size DESC; 1=table_name ASC; 2=size ASC; */
SET @list_total_size = 1
SET @filegroup_name = '%'
SET @table_name_pattern = '%'
IF @include_system_tables IS NULL
SET @include_system_tables = CASE WHEN DB_NAME() IN ('master', 'msdb', 'tempdb') THEN 1 ELSE 0 END
SET @list_filegroup_and_drive_summary = 0
DECLARE @debug smallint
DECLARE @format_counts smallint --1=',0'; 2/3=with K=1000s,M=1000000s, with 0/1 dec. places;.
DECLARE @include_schema_in_table_names bit
DECLARE @sql_startup_date datetime
DECLARE @total decimal(19, 3)
SELECT @sql_startup_date = create_date
FROM sys.databases WITH (NOLOCK)
WHERE name = 'tempdb'
SET @include_schema_in_table_names = 0
SET @format_counts = 3
SET @debug = 0
IF OBJECT_ID('tempdb.dbo.#index_missing') IS NOT NULL
DROP TABLE dbo.#index_missing
IF OBJECT_ID('tempdb.dbo.#index_operational_stats') IS NOT NULL
DROP TABLE dbo.#index_operational_stats
IF OBJECT_ID('tempdb.dbo.#index_specs') IS NOT NULL
DROP TABLE dbo.#index_specs
IF OBJECT_ID('tempdb.dbo.#index_usage') IS NOT NULL
DROP TABLE dbo.#index_usage
SELECT *
INTO #index_operational_stats
FROM sys.dm_db_index_operational_stats ( DB_ID(), NULL, NULL, NULL )
CREATE TABLE dbo.#index_specs (
object_id int NOT NULL,
index_id int NOT NULL,
min_compression int NULL,
max_compression int NULL,
drive char(1) NULL,
alloc_mb decimal(9, 1) NOT NULL,
alloc_gb AS CAST(alloc_mb / 1024.0 AS decimal(9, 3)),
used_mb decimal(9, 1) NOT NULL,
used_gb AS CAST(used_mb / 1024.0 AS decimal(9, 3)),
rows bigint NULL,
table_mb decimal(9, 1) NULL,
table_gb AS CAST(table_mb / 1024.0 AS decimal(9, 3)),
size_rank int NULL,
approx_max_data_width bigint NULL,
max_days_active int,
UNIQUE CLUSTERED ( object_id, index_id )
) --SELECT * FROM #index_specs
--**********************************************************************************************************************
PRINT 'Started @ ' + CONVERT(varchar(30), GETDATE(), 120)
DECLARE @is_compression_available bit
DECLARE @sql varchar(max)
IF (CAST(SERVERPROPERTY('Edition') AS varchar(40)) NOT LIKE '%Developer%' AND
CAST(SERVERPROPERTY('Edition') AS varchar(40)) NOT LIKE '%Enterprise%')
AND (CAST(SERVERPROPERTY('ProductVersion') AS varchar(30)) NOT LIKE '1[456789]%.%')
SET @is_compression_available = 0
ELSE
SET @is_compression_available = 1
SET @sql = '
INSERT INTO #index_specs ( object_id, index_id,' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
min_compression, max_compression,' END + '
alloc_mb, used_mb, rows )
SELECT
base_size.object_id,
base_size.index_id, ' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
base_size.min_compression,
base_size.max_compression,' END + '
(base_size.total_pages + ISNULL(internal_size.total_pages, 0)) / 128.0 AS alloc_mb,
(base_size.used_pages + ISNULL(internal_size.used_pages, 0)) / 128.0 AS used_mb,
base_size.row_count AS rows
FROM (
SELECT
dps.object_id,
dps.index_id, ' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
MIN(p.data_compression) AS min_compression,
MAX(p.data_compression) AS max_compression,' END + '
SUM(dps.reserved_page_count) AS total_pages,
SUM(dps.used_page_count) AS used_pages,
SUM(CASE WHEN dps.index_id IN (0, 1) THEN dps.row_count ELSE 0 END) AS row_count
FROM sys.dm_db_partition_stats dps ' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
INNER JOIN sys.partitions p WITH (NOLOCK) ON
p.partition_id = dps.partition_id ' END + '
--WHERE dps.object_id > 100
WHERE OBJECT_NAME(dps.object_id) LIKE ''' + @table_name_pattern + ''' AND
OBJECT_NAME(dps.object_id) NOT LIKE ''' + @table_name_exclude_pattern + '''
GROUP BY
dps.object_id,
dps.index_id
) AS base_size
LEFT OUTER JOIN (
SELECT
it.parent_id,
SUM(dps.reserved_page_count) AS total_pages,
SUM(dps.used_page_count) AS used_pages
FROM sys.internal_tables it WITH (NOLOCK)
INNER JOIN sys.dm_db_partition_stats dps WITH (NOLOCK) ON
dps.object_id = it.parent_id
WHERE it.internal_type IN ( ''202'', ''204'', ''211'', ''212'', ''213'', ''214'', ''215'', ''216'' )
GROUP BY
it.parent_id
) AS internal_size ON base_size.index_id IN (0, 1) AND internal_size.parent_id = base_size.object_id
'
IF @debug >= 1
PRINT @sql
EXEC(@sql)
--**********************************************************************************************************************
UPDATE [is]
SET approx_max_data_width = index_cols.approx_max_data_width
FROM #index_specs [is]
INNER JOIN (
SELECT index_col_ids.object_id, index_col_ids.index_id,
SUM(CASE WHEN c.max_length = -1 THEN 16 ELSE c.max_length END) AS approx_max_data_width
FROM (
SELECT ic.object_id, ic.index_id, ic.column_id
--,object_name(ic.object_id)
FROM sys.index_columns ic
WHERE
ic.object_id > 100
UNION
SELECT i_nonclus.object_id, i_nonclus.index_id, ic_clus.column_id
--,object_name(i_nonclus.object_id)
FROM sys.indexes i_nonclus
CROSS APPLY (
SELECT ic_clus2.column_id
--,object_name(ic_clus2.object_id),ic_clus2.key_ordinal
FROM sys.index_columns ic_clus2
WHERE
ic_clus2.object_id = i_nonclus.object_id AND
ic_clus2.index_id = 1 AND
ic_clus2.key_ordinal > 0 --technically superfluous, since clus index can't have include'd cols anyway
) AS ic_clus
WHERE
i_nonclus.object_id > 100 AND
i_nonclus.index_id > 1
) AS index_col_ids
INNER JOIN sys.columns c ON c.object_id = index_col_ids.object_id AND c.column_id = index_col_ids.column_id
GROUP BY index_col_ids.object_id, index_col_ids.index_id
) AS index_cols ON index_cols.object_id = [is].object_id AND index_cols.index_id = [is].index_id
UPDATE ispec
SET table_mb = ispec_ranking.table_mb,
size_rank = ispec_ranking.size_rank
FROM #index_specs ispec
INNER JOIN (
SELECT *, ROW_NUMBER() OVER(ORDER BY table_mb DESC, rows DESC, OBJECT_NAME(object_id)) AS size_rank
FROM (
SELECT object_id, SUM(alloc_mb) AS table_mb, MAX(rows) AS rows
FROM #index_specs
GROUP BY object_id
) AS ispec_allocs
) AS ispec_ranking ON
ispec_ranking.object_id = ispec.object_id
--**********************************************************************************************************************
IF @list_missing_indexes = 1
BEGIN
SELECT
IDENTITY(int, 1, 1) AS ident,
DB_NAME(mid.database_id) AS Db_Name,
CONVERT(varchar(10), GETDATE(), 120) AS capture_date,
ispec.size_rank, ispec.table_mb,
CASE WHEN @format_counts = 1 THEN REPLACE(CONVERT(varchar(20), CAST(dps.row_count AS money), 1), '.00', '')
WHEN @format_counts = 2 THEN CAST(CAST(dps.row_count * 1.0 / CASE ca1.row_count_suffix
WHEN 'M' THEN 1000000 WHEN 'K' THEN 1000 ELSE 1 END AS int) AS varchar(20)) + ca1.row_count_suffix
WHEN @format_counts = 3 THEN CAST(CAST(dps.row_count * 1.0 / CASE ca1.row_count_suffix
WHEN 'M' THEN 1000000 WHEN 'K' THEN 1000 ELSE 1 END AS decimal(14, 1)) AS varchar(20)) + ca1.row_count_suffix
ELSE CAST(dps.row_count AS varchar(20)) END AS row_count,
CASE WHEN @include_schema_in_table_names = 1 THEN OBJECT_SCHEMA_NAME(mid.object_id /*, mid.database_id*/) + '.'
ELSE '' END + OBJECT_NAME(mid.object_id /*, mid.database_id*/) AS Table_Name,
mid.equality_columns, mid.inequality_columns,
LEN(mid.included_columns) - LEN(REPLACE(mid.included_columns, ',', '')) + 1 AS incl_col_count,
mid.included_columns,
user_seeks, user_scans, NULL AS max_days_active, /*cj1.max_days_active,*/ unique_compiles,
last_user_seek, last_user_scan,
CAST(avg_total_user_cost AS decimal(9, 3)) AS avg_total_user_cost,
CAST(avg_user_impact AS decimal(9, 3)) AS [avg_user_impact%],
system_seeks, system_scans, last_system_seek, last_system_scan,
CAST(avg_total_system_cost AS decimal(9, 3)) AS avg_total_system_cost,
CAST(avg_system_impact AS decimal(9, 3)) AS [avg_system_impact%],
mid.statement, mid.object_id, mid.index_handle
INTO #index_missing
FROM sys.dm_db_missing_index_details mid WITH (NOLOCK)
INNER JOIN sys.indexes i ON i.object_id = mid.object_id AND i.index_id IN (0, 1) AND i.data_space_id <= 32767
LEFT OUTER JOIN sys.dm_db_missing_index_groups mig WITH (NOLOCK) ON
mig.index_handle = mid.index_handle
LEFT OUTER JOIN sys.dm_db_missing_index_group_stats migs WITH (NOLOCK) ON
migs.group_handle = mig.index_group_handle
LEFT OUTER JOIN sys.dm_db_partition_stats dps WITH (NOLOCK) ON
dps.object_id = mid.object_id AND
dps.index_id IN (0, 1)
OUTER APPLY (
SELECT CASE WHEN dps.row_count >= 1000000 THEN 'M' WHEN dps.row_count >= 1000 THEN 'K' ELSE '' END AS row_count_suffix
) AS ca1
OUTER APPLY (
SELECT ispec.table_mb, ispec.size_rank
FROM dbo.#index_specs ispec
WHERE
ispec.object_id = mid.object_id AND
ispec.index_id IN (0, 1)
) AS ispec
--order by
--DB_NAME, Table_Name, equality_columns
WHERE
1 = 1
AND mid.database_id = DB_ID()
AND OBJECT_NAME(mid.object_id) LIKE @table_name_pattern
ORDER BY
--avg_total_user_cost * (user_seeks + user_scans) DESC,
Db_Name,
CASE WHEN @order_by IN (-2, 2) THEN ispec.size_rank * -SIGN(@order_by) ELSE 0 END,
Table_Name,
equality_columns, inequality_columns,
user_seeks DESC
SELECT *
FROM #index_missing
ORDER BY ident
/*
IF @list_missing_indexes_summary = 1
BEGIN
SELECT
derived.Size_Rank, derived.table_mb,
derived.Table_Name, derived.Equality_Column, derived.Equality#, derived.User_Seeks,
ISNULL((SELECT SUM(user_seeks)
FROM #index_missing im2
OUTER APPLY dbo.DelimitedSplit8K (inequality_columns, ',') ds
WHERE im2.Size_Rank = derived.Size_Rank AND
LTRIM(RTRIM(ds.Item)) = derived.Equality_Column
), 0) AS Inequality_Seeks,
derived.User_Scans, derived.Last_User_Seek, derived.Last_User_Scan,
derived.Max_Days_Active, derived.Avg_Total_User_Cost, derived.Approx_Total_Cost
FROM (
SELECT
Size_Rank, MAX(table_mb) AS table_mb, Table_Name, LTRIM(RTRIM(ds.Item)) AS Equality_Column,
SUM(user_seeks) AS User_Seeks, SUM(user_scans) AS User_Scans,
MAX(last_user_seek) AS Last_User_Seek, MAX(last_user_scan) AS Last_User_Scan,
MIN(max_days_active) AS Max_Days_Active,
MAX(avg_total_user_cost) AS Avg_Total_User_Cost,
(SUM(user_seeks) + SUM(user_scans)) * MAX(avg_total_user_cost) AS Approx_Total_Cost,
MAX(ds.ItemNumber) AS Equality#
FROM #index_missing
CROSS APPLY dbo.DelimitedSplit8K (equality_columns, ',') ds
WHERE equality_columns IS NOT NULL
GROUP BY size_rank, Table_Name, LTRIM(RTRIM(ds.Item))
) AS derived
ORDER BY Size_Rank, Table_Name, Approx_Total_Cost DESC
END --IF
*/
END --IF
PRINT 'Index Usage Stats @ ' + CONVERT(varchar(30), GETDATE(), 120)
--**********************************************************************************************************************
-- list index usage stats (seeks, scans, etc.)
SELECT
IDENTITY(int, 1, 1) AS ident,
DB_NAME() AS db_name,
ispec.size_rank, ispec.alloc_mb - ispec.used_mb AS unused_mb,
CASE WHEN i.data_space_id <= 32767 THEN FILEGROUP_NAME(i.data_space_id) ELSE '{CS}' END AS main_fg_name,
CAST(NULL AS int) AS filler,
CASE WHEN @include_schema_in_table_names = 1 THEN OBJECT_SCHEMA_NAME(i.object_id /*, DB_ID()*/) + '.'
ELSE '' END + OBJECT_NAME(i.object_id /*, i.database_id*/) AS Table_Name,
key_cols AS key_cols, nonkey_cols AS nonkey_cols,
LEN(nonkey_cols) - LEN(REPLACE(nonkey_cols, ',', '')) + 1 AS nonkey_count,
CAST(NULL AS varchar(100)) AS filler2,
ius.user_seeks, ius.user_scans, --ius.user_seeks + ius.user_scans AS total_reads,
ius.user_lookups, ius.user_updates,
CASE WHEN @format_counts = 1 THEN REPLACE(CONVERT(varchar(20), CAST(dps.row_count AS money), 1), '.00', '')
WHEN @format_counts = 2 THEN CAST(CAST(dps.row_count * 1.0 / CASE ca1.row_count_suffix
WHEN 'M' THEN 1000000 WHEN 'K' THEN 1000 ELSE 1 END AS int) AS varchar(20)) + ca1.row_count_suffix
WHEN @format_counts = 3 THEN CAST(CAST(dps.row_count * 1.0 / CASE ca1.row_count_suffix
WHEN 'M' THEN 1000000 WHEN 'K' THEN 1000 ELSE 1 END AS decimal(14, 1)) AS varchar(20)) + ca1.row_count_suffix
ELSE CAST(dps.row_count AS varchar(20)) END AS row_count,
ispec.alloc_gb AS index_gb, ispec.table_gb,
SUBSTRING('NY', CAST(i.is_primary_key AS int) + CAST(i.is_unique_constraint AS int) + 1, 1) +
CASE WHEN i.is_unique = CAST(i.is_primary_key AS int) + CAST(i.is_unique_constraint AS int) THEN ''
ELSE '.' + SUBSTRING('NY', CAST(i.is_unique AS int) + 1, 1) END AS [Uniq?],
REPLACE(i.name, oa1.table_name, '~') AS index_name,
i.index_id,
ispec.approx_max_data_width AS [data_width],
CAST(CAST(ispec.used_mb AS float) * 1024.0 * 1024.0 / NULLIF(dps.row_count, 0) AS int) AS cmptd_row_size,
CASE
WHEN ispec.max_compression IS NULL THEN '(Not applicable)'
WHEN ispec.max_compression = 2 THEN 'Page'
WHEN ispec.max_compression = 1 THEN 'Row'
WHEN ispec.max_compression = 0 THEN ''
ELSE '(Unknown)' END AS max_compression,
i.fill_factor,
dios.leaf_delete_count + dios.leaf_insert_count + dios.leaf_update_count as leaf_mod_count,
dios.range_scan_count, dios.singleton_lookup_count,
DATEDIFF(DAY, STATS_DATE ( i.object_id , i.index_id ), GETDATE()) AS stats_days_old,
DATEDIFF(DAY, CASE
WHEN o.create_date > @sql_startup_date AND @sql_startup_date > o.modify_date THEN o.create_date
WHEN o.create_date > @sql_startup_date AND o.modify_date > @sql_startup_date THEN o.modify_date
ELSE @sql_startup_date END, GETDATE()) AS max_days_active,
dios.row_lock_count, dios.row_lock_wait_in_ms,
dios.page_lock_count, dios.page_lock_wait_in_ms,
ius.last_user_seek, ius.last_user_scan,
ius.last_user_lookup, ius.last_user_update,
fk.Reference_Count AS fk_ref_count,
ius2.row_num,
ius.system_seeks, ius.system_scans, ius.system_lookups, ius.system_updates,
ius.last_system_seek, ius.last_system_scan, ius.last_system_lookup, ius.last_system_update,
GETDATE() AS capture_date
INTO #index_usage
FROM sys.indexes i WITH (NOLOCK)
INNER JOIN sys.objects o WITH (NOLOCK) ON
o.object_id = i.object_id
INNER JOIN dbo.#index_specs ispec ON
ispec.object_id = i.object_id AND
ispec.index_id = i.index_id
OUTER APPLY (
SELECT CASE WHEN EXISTS(SELECT 1 FROM #index_specs [is] WHERE [is].object_id = i.object_id AND [is].index_id = 1)
THEN 1 ELSE 0 END AS has_clustered_index
) AS cj2
OUTER APPLY (
SELECT STUFF((
SELECT
', ' + COL_NAME(ic.object_id, ic.column_id)
FROM sys.index_columns ic WITH (NOLOCK)
WHERE
ic.key_ordinal > 0 AND
ic.object_id = i.object_id AND
ic.index_id = i.index_id
ORDER BY
ic.key_ordinal
FOR XML PATH('')
), 1, 2, '')
) AS key_cols (key_cols)
OUTER APPLY (
SELECT STUFF((
SELECT
', ' + COL_NAME(ic.object_id, ic.column_id)
FROM sys.index_columns ic WITH (NOLOCK)
WHERE
ic.key_ordinal = 0 AND
ic.object_id = i.object_id AND
ic.index_id = i.index_id
ORDER BY
COL_NAME(ic.object_id, ic.column_id)
FOR XML PATH('')
), 1, 2, '')
) AS nonkey_cols (nonkey_cols)
LEFT OUTER JOIN sys.dm_db_partition_stats dps WITH (NOLOCK) ON
dps.object_id = i.object_id AND
dps.index_id = i.index_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats ius WITH (NOLOCK) ON
ius.database_id = DB_ID() AND
ius.object_id = i.object_id AND
ius.index_id = i.index_id
LEFT OUTER JOIN (
SELECT
database_id, object_id, MAX(user_scans) AS user_scans,
ROW_NUMBER() OVER (ORDER BY MAX(user_scans) DESC) AS row_num --user_scans|user_seeks+user_scans
FROM sys.dm_db_index_usage_stats WITH (NOLOCK)
WHERE
database_id = DB_ID()
--AND index_id > 0
GROUP BY
database_id, object_id
) AS ius2 ON
ius2.database_id = DB_ID() AND
ius2.object_id = i.object_id
LEFT OUTER JOIN (
SELECT
referenced_object_id, COUNT(*) AS Reference_Count
FROM sys.foreign_keys WITH (NOLOCK)
WHERE
is_disabled = 0
GROUP BY
referenced_object_id
) AS fk ON
fk.referenced_object_id = i.object_id
LEFT OUTER JOIN #index_operational_stats dios ON
dios.object_id = i.object_id AND
dios.index_id = i.index_id
OUTER APPLY (
SELECT OBJECT_NAME(i.object_id/*, DB_ID()*/) AS table_name
) AS oa1
OUTER APPLY (
SELECT CASE WHEN dps.row_count >= 1000000 THEN 'M' WHEN dps.row_count >= 1000 THEN 'K' ELSE '' END AS row_count_suffix
) AS ca1
WHERE
--i.object_id > 100 AND
(i.is_disabled = 0 OR @order_by IN (-1, 1)) AND
i.is_hypothetical = 0 AND
i.data_space_id <= 32767 AND
--i.type IN (0, 1, 2) AND
o.type NOT IN ( 'IF', 'IT', 'TF', 'TT' ) AND
(
o.name LIKE @table_name_pattern AND
o.name NOT LIKE 'dtprop%' AND
o.name NOT LIKE 'filestream[_]' AND
o.name NOT LIKE 'MSpeer%' AND
o.name NOT LIKE 'MSpub%' AND
--o.name NOT LIKE 'tmp[_]%' AND
--o.name NOT LIKE 'queue[_]%' AND
--(DB_NAME() IN ('master', 'msdb') OR o.name NOT LIKE 'sys%')
(@include_system_tables = 1 OR o.name NOT LIKE 'sys%')
--AND o.name NOT LIKE 'tmp%'
) AND
(@filegroup_name IS NULL OR CASE WHEN i.data_space_id <= 32767 THEN FILEGROUP_NAME(i.data_space_id) ELSE '{CS}' END LIKE @filegroup_name) AND
(@max_compression IS NULL OR ispec.max_compression <= @max_compression)
ORDER BY
--cj2.has_clustered_index, ispec.size_rank, --heaps first, by size
db_name,
--i.index_id,
--ius.user_seeks - ius.user_scans,
CASE WHEN @order_by IN (-2, 2) THEN ispec.size_rank * -SIGN(@order_by) ELSE 0 END,
--ius.user_scans DESC,
--ius2.row_num, --user_scans&|user_seeks
table_name,
-- list clustered index first, if any, then other index(es)
CASE WHEN i.index_id IN (0, 1) THEN 1 ELSE 2 END,
key_cols
OPTION (MAXDOP 3, RECOMPILE)
SELECT *
FROM #index_usage
ORDER BY ident
IF @list_total_size > 1
SELECT SUM(index_gb) AS Total_Size_GB
FROM #index_usage
IF @list_filegroup_and_drive_summary = 1
SELECT
LEFT(df.physical_name, 1) AS drive,
FILEGROUP_NAME(au_totals.data_space_id) AS filegroup_name,
au_totals.total_mb AS total_fg_mb,
au_totals.used_mb AS used_fg_mb,
au_totals.total_mb - au_totals.used_mb AS free_fg_mb,
CAST(df.size / 128.0 AS decimal(9, 3)) AS file_size_mb
FROM (
SELECT
au.data_space_id,
CAST(SUM(au.total_pages) / 128.0 AS decimal(9, 3)) AS total_mb,
CAST(SUM(au.used_pages) / 128.0 AS decimal(9, 3)) AS used_mb
FROM sys.allocation_units au
INNER JOIN sys.filegroups fg ON
fg.data_space_id = au.data_space_id
GROUP BY au.data_space_id WITH ROLLUP
) AS au_totals
INNER JOIN sys.database_files df ON
df.data_space_id = au_totals.data_space_id
ORDER BY filegroup_name, drive
PRINT 'Ended @ ' + CONVERT(varchar(30), GETDATE(), 120)
SET DEADLOCK_PRIORITY @deadlock_priority
IF @transaction_isolation_level = 1
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
ELSE
IF @transaction_isolation_level = 2
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
ELSE
IF @transaction_isolation_level = 3
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
ELSE
IF @transaction_isolation_level = 4
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
ELSE
IF @transaction_isolation_level = 5
SET TRANSACTION ISOLATION LEVEL SNAPSHOT