I've imported my emails directly to a SQL server database. So I have one table with just blobs of unstructured data. And I also have a product table in my database.
Example:
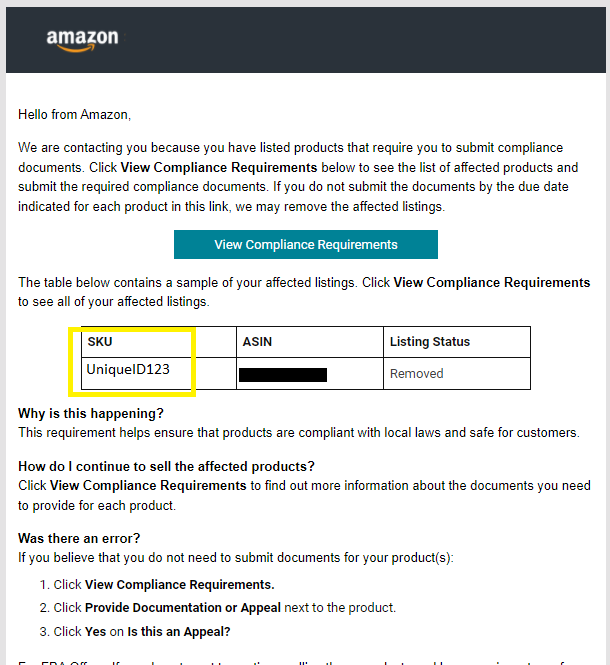
Is there an efficient (or semi-reasonable) way to query to see if each SKU (product id) exists in that unstructured blob? I have 50K products, and 1K emails like this.
If it is not reasonable to do in TSQL, I would use Python/Regex, but this would be easier.
Lets assume that the data looks like this.
CREATE TABLE #email_content (email_blob nvarchar(max));
INSERT INTO #email_content (email_blob) VALUES ('Some content to extract a unique thing UniqueID123. More data, not structured');
CREATE TABLE #product_table (sku nvarchar(max));
INSERT INTO #product_table (sku)
VALUES ('UniqueID123')
, ('UniqueID456')
, ('UniqueID789')
, ('UniqueIDABC')
, ('UniqueIDDEF')
, ('UniqueIDGHI')
;
EDIT - this is my first crack at it. Though I don't know if it can be made more efficient
SELECT
[eco].[email_blob]
, [pta].[sku]
FROM #email_content eco
CROSS APPLY #product_table pta
WHERE [eco].[email_blob] LIKE '%' + [pta].[sku] + '%'