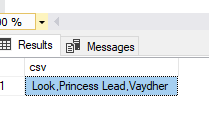
For the last column here the patient collaterals I want to combine the last column cv.full_name as there will be multiple ollaterals for the patient.
I want to have a subquery that will take each collateral and add a column to the data set: I'm not sure where to put this (select sq.full_name from colateral_view sq as Collateral1)
But how do I loop this so that I get all of the patients collaterals?
select distinct ac.first_name, ac.last_name, ac.id_no, ac.dob, st.description, co.description,
rd.race, rd.ethnicity_description, pe.program_name, ih.income_amount, cv.full_name from address ad
inner join all_clients_view ac
on ad.people_id = ac.people_id
inner join county co
on ad.county = co.county_id
inner join state st
on co.state_id = st.state_id
inner join rpt_demographics rd
on ad.people_id = rd.people_id
right join program_enrollment_expanded_view pe
on pe.people_id = ac.people_id
inner join income_history_view ih
on ac.people_id = ih.people_id
right join colaterals_view cv
on ad.people_id = cv.people_id
where ad.is_active = 1 and cv.event_name in('Personal Collateral', 'Family')