True; MERGE is badly implemented in SQL Server, especially with regards to locking and the subsequent blocking, but in my experience it is not too bad if used only for UPDATES.
The problem with UPDATE JOIN is that it allows indeterminate values to be updated.
The following is a simple example to update a header table with the minimum value in a detail table.
With this test data:
CREATE TABLE #h
(
hid int NOT NULL PRIMARY KEY
,MinDValue int NULL
);
INSERT INTO #h(hid) VALUES (1),(2),(3);
CREATE TABLE #d
(
hid int NOT NULL
,DValue int NOT NULL
);
INSERT INTO #d
VALUES (1, 1), (1, 2)
,(2, 1), (2, 2)
,(3, 1), (3, 2);
the following will appear to work:
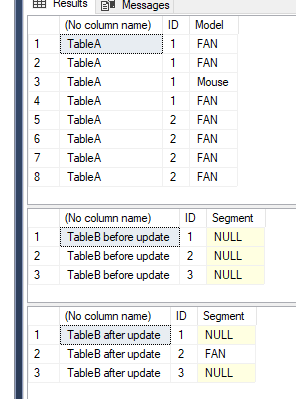
UPDATE H
SET MinDValue = D.DValue
FROM #h H
JOIN #d D
ON H.hid = D.hid;
as the UPDATE statement will take the first value which, with a small table under low loading, will always be in the order the data is entered.
Now we know that a table is an unordered set and the UPDATE statement is wrong but do you want to reply on all your developers knowing this or do you want 'random bugs' in production code?
If they tried that with MERGE:
MERGE #h H
USING
(
SELECT hid, DValue
FROM #d
) S
ON H.hid = S.hid
WHEN MATCHED
THEN UPDATE
SET MinDValue = S.DValue;
they would get an informative exception and be forced to write:
MERGE #h H
USING
(
SELECT hid, MIN(DValue) AS DValue
FROM #d
GROUP BY hid
) S
ON H.hid = S.hid
WHEN MATCHED
THEN UPDATE
SET MinDValue = S.DValue;
If you really object to MERGE you could get them to have a working MERGE statement as a comment before writing the UPDATE statement.
Microsoft will never change the way UPDATE works but they could add a global STRICT type option sometime to give the 'statement attempted to UPDATE the same row more than once' exception.