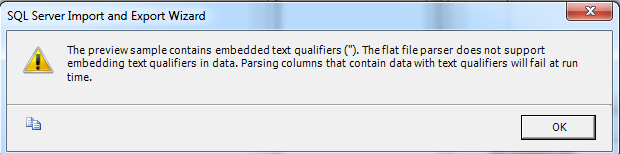
Here's my current code:
CREATE TABLE tmp_OKFF
(
OKCCY VARCHAR(5),
OKBRNM VARCHAR(6),
OKONPX VARCHAR(17),
OKONPM VARCHAR(17),
OKFRX VARCHAR(19),
OKFPX VARCHAR(19),
OKMRX VARCHAR(17),
OKMPX VARCHAR(17),
OKSEQ VARCHAR(3)
)
BULK INSERT tmp_OKFF
FROM 'C:\sample.CSV'
WITH (FORMATFILE='C:\sample.fmt')
Here's the data I want to insert in my tmp_OKFF
"ABC","0001",-990039739 ,0 ,0 ,0 ,0 ,0 ,0
"ABC"," ",-3422054702 ,0 ,481385 ,0 ,0 ,0 ,0
"XXX","0001",0 ,0 ,0 ,0 ,0 ,0 ,0
"ASD"," ",0 ,0 ,0 ,0 ,0 ,0 ,0
"JED","0001",21644944 ,0 ,0 ,0 ,0 ,0 ,0
"FAQ"," ",74815363 ,0 ,0 ,11120 ,0 ,0 ,0
"PHP","0002",905175206 ,0 ,0 ,0 ,0 ,0 ,0
Here's the exact format:
12.0
10
1 SQLCHAR 0 1 """ 0 ""
2 SQLCHAR 0 3 "","" 1 OKCCY SQL_Latin1_General_CP1_CI_AS
3 SQLCHAR 0 4 ""," 2 OKBRNM SQL_Latin1_General_CP1_CI_AS
4 SQLCHAR 0 17 "," 3 OKONPX SQL_Latin1_General_CP1_CI_AS
5 SQLCHAR 0 17 "," 4 OKONPM SQL_Latin1_General_CP1_CI_AS
6 SQLCHAR 0 19 "," 5 OKFRX SQL_Latin1_General_CP1_CI_AS
7 SQLCHAR 0 19 "," 6 OKFPX SQL_Latin1_General_CP1_CI_AS
8 SQLCHAR 0 17 "," 7 OKMRX SQL_Latin1_General_CP1_CI_AS
9 SQLCHAR 0 17 "," 8 OKMPX SQL_Latin1_General_CP1_CI_AS
10 SQLCHAR 0 3 "\r" 9 OKSEQ SQL_Latin1_General_CP1_CI_AS