Hello all,
I apologize in advance if I am posting incorrectly, I am new to SQLTeam ![]() . I am seeking help with an issue I've been having in SSIS; I have been working on creating/loading data into a database for a school project and have been having some issues with Merge Join. I’ve researched many issues the others have had with Merge Join and typically solve my own problems but this one is a bit tricky. I’ve created an SSIS package that should pull a column from a table in Access (this column contains duplicate names to which I utilize a sort later on in the data flow) as well as pull another column from a table in my SQL Server database. For both of these OLE DB Sources I have tried using the simple method of selecting the table through the data access mode but I thought perhaps this was contributing to many warning messages because it would always pull everything from the table as opposed to the one column from each that I wanted. I am now using the SQL Command option with an extremely simple query.
. I am seeking help with an issue I've been having in SSIS; I have been working on creating/loading data into a database for a school project and have been having some issues with Merge Join. I’ve researched many issues the others have had with Merge Join and typically solve my own problems but this one is a bit tricky. I’ve created an SSIS package that should pull a column from a table in Access (this column contains duplicate names to which I utilize a sort later on in the data flow) as well as pull another column from a table in my SQL Server database. For both of these OLE DB Sources I have tried using the simple method of selecting the table through the data access mode but I thought perhaps this was contributing to many warning messages because it would always pull everything from the table as opposed to the one column from each that I wanted. I am now using the SQL Command option with an extremely simple query.
SELECT DISTINCT Name
FROM NameTable
For both OLE DB sources the query is the same except for the parameters selected. Following the source, I have a data conversion on each (because I found that Merge Join is a pansy when the data types don’t match) and I convert the Access one from DT_WSTR to DT_STR, while the SQL Server source is converted from DT_I4 to DT_STR. I then follow both with a sort, passing through the copy of Name and Tid, checking the “removing sorts with duplicate rows” option. Following that step, I then begin utilizing Merge Join with the Access source being my left input and the SQL Server Source (by source I am just referring to the side of the data flow, you’ll see in the image below) being the right input. Below I will also show how I am configuring the Merge Join, in case I’m doing it wrong. Lastly, I have my OLE DB Destination setup to drop this data into a table with the following columns, PrimaryKey column (it auto increments as new data is inserted), the Name column and the Tid column.
When I run the columns it says that it succeeds with no errors. I check my database and nothing has been written, I also note that in SSIS it says 0 rows written. I’m not sure what is going on as I enable the data viewers in between the sorts and the merge join and can see the data coming out both pipelines. Another important thing to note is that when I enable the data viewer after the Merge Join, it never shows up when I run the package, only the two after sort appear. At first I thought maybe the data wasn’t coming out of the Merge Join so I experimented with placing derive columns after the Merge Join and sure enough, the data does flow through. Even with those extra things in between the Merge Join and Destination, the data viewers never pop up. I mention this because I suspect that this is part of the problem. Below are also the messages that SSIS spits out after I run the package.
SSIS Messages:
SSIS package "C:\Users\Liono\Documents\Visual Studio 2015\Projects\DataTest6\Package.dtsx" starting.
Information: 0x4004300A at Data Flow Task, SSIS.Pipeline: Validation phase is beginning.
Information: 0x4004300A at Data Flow Task, SSIS.Pipeline: Validation phase is beginning.
Information: 0x40043006 at Data Flow Task, SSIS.Pipeline: Prepare for Execute phase is beginning.
Information: 0x40043007 at Data Flow Task, SSIS.Pipeline: Pre-Execute phase is beginning.
Information: 0x4004300C at Data Flow Task, SSIS.Pipeline: Execute phase is beginning.
Information: 0x40043008 at Data Flow Task, SSIS.Pipeline: Post Execute phase is beginning.
Information: 0x4004300B at Data Flow Task, SSIS.Pipeline: "OLE DB Destination" wrote 0 rows.
Information: 0x40043009 at Data Flow Task, SSIS.Pipeline: Cleanup phase is beginning.
SSIS package "C:\Users\Liono\Documents\Visual Studio 2015\Projects\DataTest6\Package.dtsx" finished: Success.
The program '[9588] DtsDebugHost.exe: DTS' has exited with code 0 (0x0).
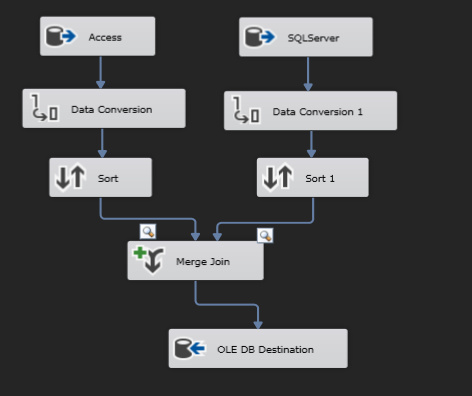
EDIT: I couldn't show a picture of my merge join but the left input is that Name data and the right input is the id number being joined.
Lastly, I did have a somewhat similar issue before and I solved it on my own by using one source with the right SQL query, but the same thing doesn’t apply here because I’m pulling from two different sources and I am having issues with the Merge Join this time around. The code I used last time:
SELECT a.T1id,
b.T2id,
c.Nameid
FROM Table1 AS a join
Table2 AS b
On a.T1id = b.T2id,
Name AS c
ORDER BY a.[T1id] ASC
I post this because, maybe someone might know of a way to right some SQL that will allow me to forgo using Merge Join again, where I can somehow grab both sets of data and join them, then dump them in my table in SQL Server.
As always, I greatly appreciate your help and if there are any questions of clarifications that need to be made, please ask and I will do my best to help you help me.
Thanks!