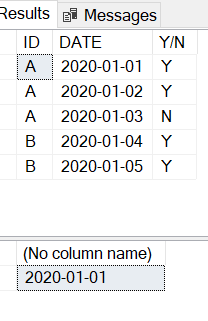
I.e. the value of the first column, then the min date of the second column for the records corresponding to the value of the first column, and then the Y/N value corresponding to the min date calculated.
Do you want the row with the minimum date - or just the minimum date?
With myData
As (
Select *
, rn = row_number() over(Partition By ID Order By DATE)
From #SampleData
Where [Y/N] = 'Y' --only select the rows with 'Y'
)
Select *
From myData
Where rn = 1;
If you only have those 3 columns - and you don't need any additional columns:
Select ID
, [DATE] = min([DATE)
, [Y/N]
From #SampleData
Where [Y/N] = 'Y'
Group By
[ID]
, [Y/N]
What is the purpose for this - what are you trying to accomplish?
No - that code is not 'working' as a WHERE clause.
[DATE] = min([DATE])
Returns a column 'named' [DATE] with the minimum value of the [DATE] column from the source table based on the grouping. It might be better written as:
MinDate = min([DATE])
Or
min([DATE]) As MinDate
To clarify - you want all columns from the source table with the minimum date for each ID? So there are columns you want returned that you did not include in the sample data? If so - then use row_number() to identify the rows...
Note: if the purpose of this is to delete duplicates then change the order in the window to DESC and select all rn > 1.
To get the latest row for each partition - change the ORDER BY to a DESC order. That will identify the latest row as rn = 1, the next latest as rn = 2, etc...
Then - you can just select for rn = 1 to get the latest row for each partition.
I don't understand your other question...there is no setting of variables needed. The construct is a common-table expression that creates a 'table' named 'myData' that is then queried in the final portion of the query. This allows us to generate the row number - then filter using the results of the row number calculation.
Personally - I will use a CTE instead of a derived table where there is no need to correlate the derived table with values from the current row. When I do need to correlate the derived table I then use an OUTER/CROSS APPLY on the derived table/query.
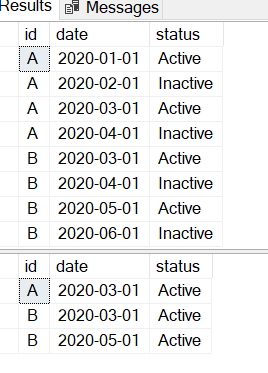
I want to:
SELECT *
FROM TABLE
WHERE (the min Active date for each ID) > 02/01/2020
A 01/01/2020 Active
A 02/01/2020 Inactive
A 03/01/2020 Active
A 04/01/2020 Inactive
B 03/01/2020 Active
B 04/01/2020 Inactive
B 05/01/2020 Active
B 06/01/2020 Inactive
Any idea?
I still don't get how to calculate MIN/MAX after applying filters. In DAX, this can be done very neatly, like: CALCULATE(MIN(DATE),FILTER(TABLE,ID=EARLIER(ID),STATUS=ACTIVE)
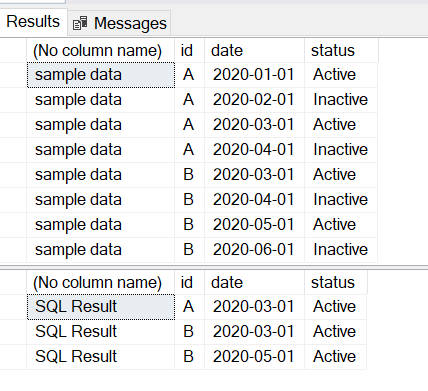
Thanks but the min Active Date of A, is 01/01/2020, so it should not be returned, because I want to specify the filter: "min Active Date > 02/01/2020".
In your results, you show: A, 2020-03-01, Active
I want this filtered out because there is a A, 2020-01-01, Active, which is an active date less than 02-01-2020.