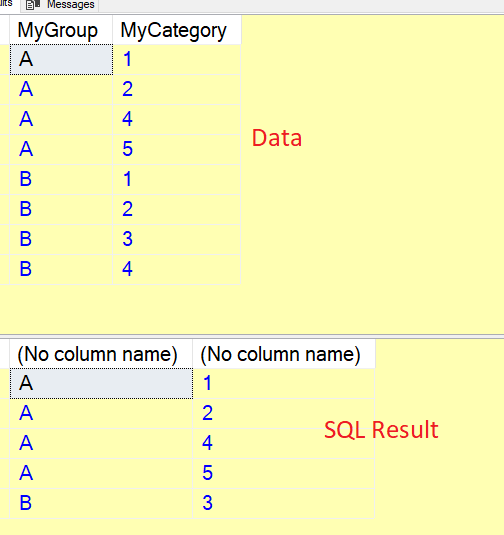
I think got what I needed but just want to know if there is a better way to approach this.
Basically, if the group contains a value (in this case the value 3), then grab only that record for that group. Otherwise, if it does not have that value, then grab all records for that group.
DROP TABLE IF EXISTS #TEMPTABLE
CREATE TABLE #TEMPTABLE
(
MyGroup VARCHAR(20)
, MyCategory TINYINT
)
INSERT INTO #TEMPTABLE VALUES
('A', 1)
, ('A', 2)
, ('B', 1)
, ('B', 2)
, ('B', 3)
, ('B', 4)
DROP TABLE IF EXISTS #TEMPTABLE_SelectedValue
SELECT * INTO #TEMPTABLE_SelectedValue FROM #TEMPTABLE
WHERE MyCategory IN (3)
--SELECT * FROM #TEMPTABLE_SelectedValue;
SELECT * FROM #TEMPTABLE T1
WHERE MyGroup NOT IN (SELECT DISTINCT MyGroup FROM #TEMPTABLE_SelectedValue)
UNION
SELECT * FROM #TEMPTABLE_SelectedValue
That is very cool HarishGG1.
I was wondering if there is a trick with OVER Partition By or filtering out a GROUP on a HAVING clause if the group contains a specific value. Otherwise, yeah, I will take the above answer too. Thank You
hi
another way of doing this .. this looks compact
; with cte as ( select MyGroup from #TEMPTABLE where MyCategory = 3 )
select distinct
case when a.Mygroup is null then b.MyGroup else a.MyGroup end
,case when a.Mygroup is null then b.MyCategory else 3 end
from cte a
right join
#TEMPTABLE b
on a.MyGroup = b.MyGroup
3 Likes
I made a mistake. On smaller row sets, @harishgg1 's code produced a CROSS JOIN. On larger row sets, it does not... not even without indexes. I'd use that code.
Really nice both computationally and readability, @harishgg1.
p.s. I tried a GROUP BY, Divide'n'Conquer, GROUP BY/Having, and Window function. I didn't try any of them with an index. They all ended up making some pretty bad sucking sounds on a 52,000 row test table when it came to reads. @harishgg1 's code was the clear and certain winner of all that.
2 Likes
Thanks for the confirmation JeffModen. I actually like @ harishgg1 original code with the full join. But I will take the CTE as well. Thank You