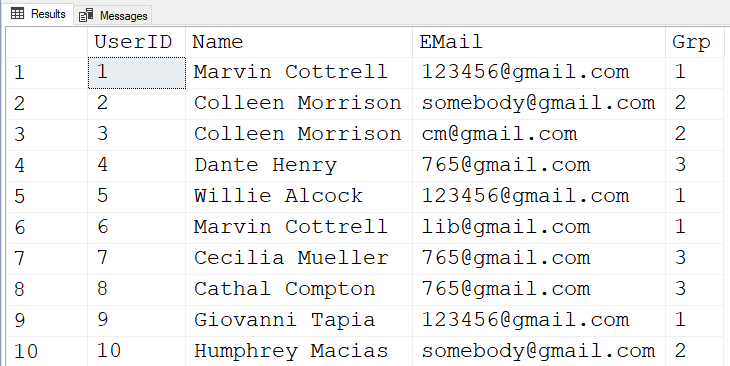
I need to group users so that they are grouped together if they have the same name or email. That is, to combine them into one group it is not necessary that everyone has the same e-mail or name, it is enough that the name or e-mail coincides with at least one other user. The desired result in the picture.
I've tried using Dense_Rank for name and email, but I don't know if I can combine them.
I would also be grateful if you tell me where I can find information on this topic, since at the moment I don’t even know how to correctly formulate a query in Google
create table #a (UserID int, Name varchar(25), Email Varchar(50))
@w1ll0w - What version of SQL Server are you using?
While we're waiting, you should change the specs on the UserID column in the #a table as follows...
create table #a (UserID int NOT NULL PRIMARY KEY CLUSTERED, Name varchar(25), Email Varchar(50))
.This problem is a little bit like the infamous "fill the bins" problem in that each iteration depends on the result of the previous operation. It's also a little bit like a hierarchy but I hate Recursive CTEs and so did it the "old fashioned" way.
And, I used a couple of tricks with index on the target table to try to decrease the number of page splits that will occur because of the out of order fill of tthe clustered index. The row count of your test data isn't big enough to be able to tell for sure. MS prefers scans over seeks for such small stuff.
Here's the code. It returns the exact result you had from your picture.
DROP TABLE IF EXISTS #Result; --Just to make reruns easier in SSMS
GO
--===== Create the result table
CREATE TABLE #Result
(
UserID INT NOT NULL
,Name VARCHAR(25)
,EMail VARCHAR(50)
,Grp INT NOT NULL
)
;
--===== Notice the "trick" Clustered Index being created.
-- It will ignore any duplicates, just in case I didn't do the "gazintas" right.
CREATE UNIQUE CLUSTERED INDEX ByUserID ON #Result (UserID) WITH (IGNORE_DUP_KEY = ON, FILLFACTOR = 10);
;
DECLARE @SearchForUserID INT
,@Grp INT = 0;
WHILE 1=1
BEGIN
--===== Find the next eligible ID that hasn't already been included in #Result
SELECT TOP 1
@SearchForUserID = UserID
,@Grp += 1
FROM #a t1
WHERE NOT EXISTS (SELECT UserID FROM #Result t2 WHERE t1.UserID = t2.UserID)
ORDER BY t1.UserID
;
--===== If an outstanding UserID was not found,
-- there's nothing left to do and we can Break out of the loop now.
IF @@ROWCOUNT = 0 BREAK
;
--===== Insert the row we find and any rows that are immediately related by Email or Name.
-- Each iteration will form a new group.
INSERT INTO #Result WITH (TABLOCK) --Minimal logging and enforces Fill Factor on 1st insert
(UserID, Name, Email, Grp) --which will help prevent massive pages splits at the beginning.
SELECT ca.*, Grp = @Grp
FROM #a t1
CROSS APPLY (SELECT t2.* FROM #a t2 WHERE t1.Email = t2.EMail OR t1.Name = t2.Name)ca
WHERE t1.UserID = @SearchForUserID
ORDER BY ca.UserID
;
END
;
--===== Let's see the result.
SELECT * FROM #Result
;
Here are the results from the code above using the readily consumable test data you kindly provided.
@JeffModen I`m using SQL Server 2016
Thanks a lot for your help and answer. I need some time to understand it. I am very grateful to you for the detailed answer.
@w1ll0w - I just noticed the words "formulate a query in Google" in your original request. Neither do I. The query I posted is for SQL Server.
As for figuring out the code, the loop works just like you'd do it as a human. To summarize...
-- 1. Get a blank sheet of paper and write down the group number as 0.
-- 2. Create the groups one group at a time
-- A. Add 1 to the group number on the new sheet of paper.
-- B. Look at the first row on the old paper in order by UserID that hasn't
-- already been copied to the new paper and put your finger on it.
-- C. IF there aren't any un-copied rows left, we can proceed to Step 3.
-- D. Copy the row you have have your finger on and any rows that match the
-- name or email address of that row to the new paper.
-- E. Loop back to step 2.A.
-- 3. Display the marked rows sorted by UserID
Hi @JeffModen
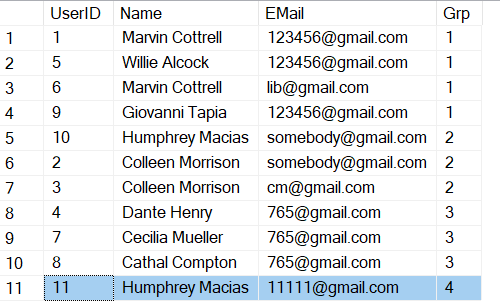
I'm still working with your solution, but I saw that it doesn't work in some cases. To demonstrate this, I added one more row to the test dataset (row 11). This new user must be added to the existing group 2 because its name is the same as one of the users in group 2. But it ends up in a separate fourth group. Could there be an addition for such a case?
create table #a (UserID int, Name varchar(25), Email Varchar(50))