select distinct(group_name), COUNT(group_name) as total, Username, phoneid from PhoneNumber_Groups_Numbers group by Group_Name, Username, phoneid order by Username asc
SELECT group_name,
COUNT(group_name) AS total,
Username,
phoneid
FROM PhoneNumber_Groups_Numbers
GROUP BY Group_Name,
Username,
phoneid
ORDER BY Username ASC
That is to be expected. When you include the "Group_Name" column in the group by clause, the query treats each Group_Name as a separate group, and of course there will be only one Group_Name in each of those groups. So perhaps what you need is the following:
SELECT
COUNT(group_name) AS total,
Username,
phoneid
FROM PhoneNumber_Groups_Numbers
GROUP BY
Username,
phoneid
ORDER BY Username ASC
If that does not quite give you the results you are looking for, can you post some sample data and the corresponding output you are trying to get?
The general rule to remember is that when you have an aggregate function such as COUNT, SUM, AVG etc. in the SELECT clause, every column in the select list that is not inside of one of those aggregate functions must be listed in the GROUP BY clause.
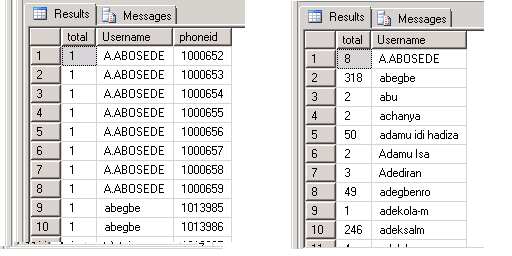
Your first query has four columns in the select list, but the second image shows only two.
I am not able to discern exactly what you are looking for based on the screen shots. If you can visualize how SQL processes your request, you might be able to fix the problem yourself. To that end, suppose you have a query like shown below:
SELECT
username,
groupname,
COUNT(*) AS Total
FROM
PhoneNumber_Groups_Numbers
GROUP BY
username,
groupname
In this case, what SQL Server does is to walk through every row in you table, look at the values of username and groupname (the columns in the group by list), and put them into buckets that have the same username and groupname. Then, it counts the entries in each bucket and reports the count as the Total.
Given that, if you also add PhoneID to the select list, which then forces you to put PhoneID into the group by list, each bucket will have a unique combination of username, groupname and PhoneID. But there can be only one row in each of those buckets because PhoneID is the primary key, and by definition, there can be only one row in the table with a given PhoneID.
To put it another way, suppose you had only two rows in your entire table like shown below:
username = abu, phoneid = 100652, groupname = abcd
username = abu, phoneid = 222222, groupname = abcd
What is the output you are looking for in this case?
I think we are going in circles So, going back to my original question: Suppose you had only two rows in your table. Nothing else - just these two rows. What is the output you want to get?
If you want to get the phoneid also in the output, along with the count of rows that have the same username and groupname, perhaps this might be what you are looking for:
SELECT
phoneid,
username,
groupname,
COUNT(*) OVER (PARTITION BY username, groupname) AS Total
FROM
PhoneNumber_Groups_Numbers
As an aside, performing these types of counts is something that SQL Server is built for, and is very good at. Almost any one of the people who answers questions on this forum would be able to write the query you need easily. The issue though is that you have to provide a correct, representative sample input data and the exact output that you are looking for, along with the logic to be used if it is not obvious from the input+output combination.
 So, going back to my original question: Suppose you had only two rows in your table. Nothing else - just these two rows. What is the output you want to get?
So, going back to my original question: Suppose you had only two rows in your table. Nothing else - just these two rows. What is the output you want to get?