Hi All,
Hope you are doing well. I am trying to finding the number of same products bought in different states in comparison to a particular state. I need to repeat this for all the states in which at least one product has been bought. For example if products ez12,ty234, Kl213 has been bought in michigan then I need to check the other states such as ohio, newyork and so on with the number of products among the three (ez12,ty234, Kl213) that has been bought in Michigan... I need to do the same thing for all the states keeping one state constant and comparing the products bought in that state to all the other states..
##Input
create table ##input
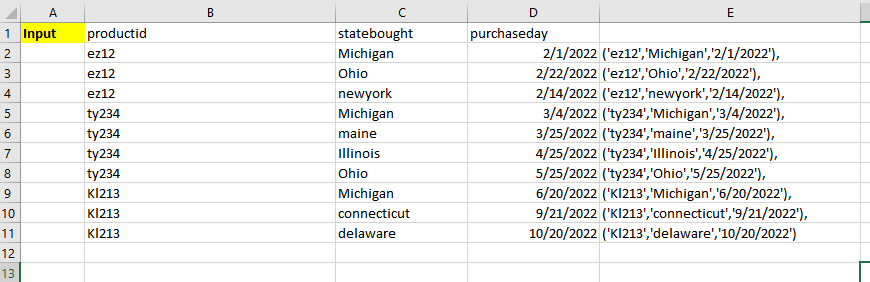
(productid varchar(20),
statebought varchar(30),
purchaseday date)
insert into ##input values
('ez12','Michigan','2/1/2022'),
('ez12','Ohio','2/22/2022'),
('ez12','newyork','2/14/2022'),
('ty234','Michigan','3/4/2022'),
('ty234','maine','3/25/2022'),
('ty234','Illinois','4/25/2022'),
('ty234','Ohio','5/25/2022'),
('Kl213','Michigan','6/20/2022'),
('Kl213','connecticut','9/21/2022'),
('Kl213','delaware','10/20/2022')
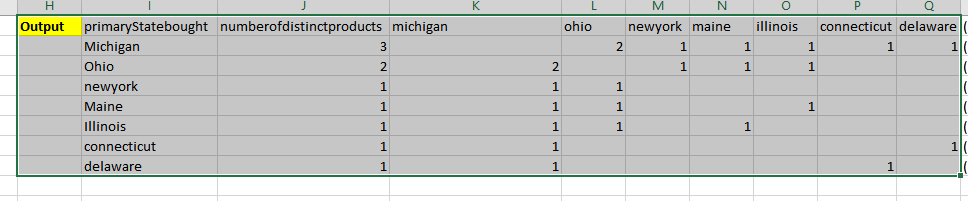
##output
('primaryStatebought ','numberofdistinctproducts','michigan','ohio','newyork','maine','illinois','connecticut','delaware'),
('Michigan','3','','2','1','1','1','1','1'),
('Ohio','2','2','','1','1','1','',''),
('newyork','1','1','1','','','','',''),
('Maine','1','1','1','','','1','',''),
('Illinois','1','1','1','','1','','',''),
('connecticut','1','1','','','','','','1'),
('delaware','1','1','','','','','1',''),
Can you please help me here.. Please find below the snapshot of the input and output tables.
Thanks,
Arun