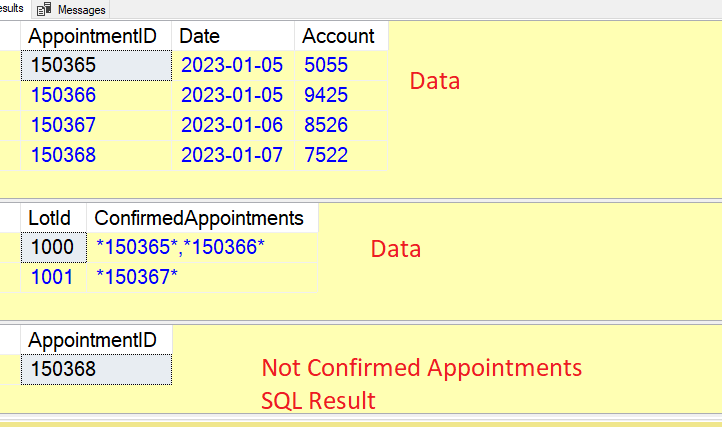
I have an application which confirms appointments by lot. It is represented in the 2 tables as follows:
Table #1: Appointments (Here, the AppointmentID fields is an Integer)
AppointmentID Date Account
150365 2023-01-05 5055
150366 2023-01-05 9425
150367 2023-01-06 8526
150368 2023-01-07 7522
Table #2: Lots of confirmed appointments (Here, ConfirmedAppointments is a varchar showing all AppointmentIDs having been confirmed in each lot)
LotID ConfirmedAppointments
1000 *150365*,*150366*
1001 *150367*
I need a query which will find all appointments which have not been confirmed. I've tried stuff like:
Select AppointmentID from Appointments where charindex('*' + cast(AppointmentID as varchar) + '*', SELECT STRING_AGG (ConfirmedAppointments, ',') FROM Lots) = 0
I'm probably coming at this all wrong but I can't see the easy solution. Basically, I'm looking for an Instr (String1, Select String2 from Table) function. Any assistance would be appreciated. Thanks!
;WITH CTE(apptID) AS (SELECT CAST(REPLACE(STRING_SPLIT(ConfirmedAppointments, ','),'*','') as int)
FROM Lots)
SELECT AppointmentID FROM Appointments
EXCEPT
SELECT apptID FROM cte;
Thanks Robert, I would not have found my way to such a query by myself. But now, it appears that I can't use your solution because String_Split is only available with SQL Server 2022 and some of my clients go as far back as SQL Server 2008. So I need to stick with more traditional and perhaps less efficient alternatives.... Thanks for your contribution though !
hi
this is your answer
; with cte as
(
select
a.AppointmentID
from
#Appointments a , #ConfirmedAppointments b
where
b.ConfirmedAppointments like '%'+cast(a.AppointmentID as nvarchar)+'%'
)
select AppointmentID from #Appointments where AppointmentID NOT IN ( select AppointmentID from cte )
hi
another way to do it
select
a.AppointmentID , count(*)
from
#Appointments a , #ConfirmedAppointments b
where
PATINDEX('%' + cast(a.AppointmentID as varchar) + '%', b.ConfirmedAppointments) = 0
group by
a.AppointmentID
having
count(*) >1
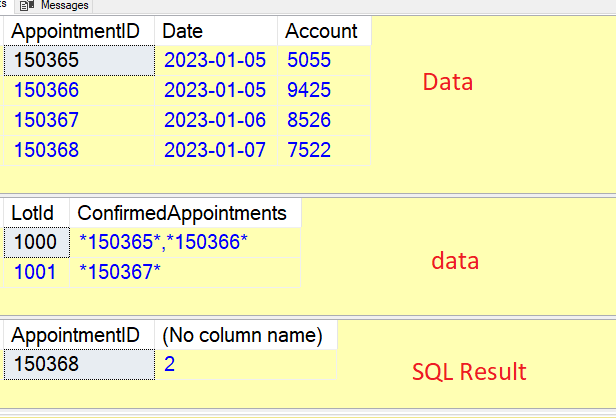
Ahhh, this works perfectly! I really need to get better read on Select queries containing multiple tables (a, b). Thank you soooooo much for taking the time to read and fully understand my post. Really, really appreciate it !!!
You really should split the confirmed appointment ids rather than trying to do string matches. dbo.DelimitedSplit8K is a high-performance function used to split data columns. You can Google the code for that function, but I will also post it here next.
If you do insist on using string matches, then for accurate results, you must include the *s in the comparison. Otherwise you can get false matches.
SELECT a.*
FROM #Appointments a
LEFT OUTER JOIN (
SELECT REPLACE(ds.Item, '*', '') AS AppointmentID
FROM #ConfirmedAppointments ca
CROSS APPLY dbo.DelimitedSplit8K(ca.ConfirmedAppointments, ',') AS ds
) AS ca ON ca.AppointmentID = a.AppointmentID
WHERE ca.AppointmentID IS NULL
SET ANSI_NULLS ON
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION [dbo].[DelimitedSplit8K] (
@pString varchar(8000),
@pDelimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
/*SELECT * FROM dbo.DelimitedSplit8K('ab/c/def/ghijklm/no/prq/////st/u//', '/')*/
RETURN
/*Inline CTE-driven "tally table" produces values from 0 up to 10,000: enough to cover varchar(8000).*/
WITH E1(N) AS (SELECT N FROM (VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) AS Ns(N)),
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
ctetally(N) AS (/* This provides the "zero base" and limits the number of rows right up front,
for both a performance gain and prevention of accidental "overruns". */
SELECT 0 UNION ALL
SELECT TOP (DATALENGTH(ISNULL(@pString, 1))) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
), cteStart(N1) AS ( /* This returns N+1 (starting position of each "element" just once for each delimiter). */
SELECT t.N+1
FROM ctetally t
WHERE (SUBSTRING(@pString,t.N,1) = @pDelimiter OR t.N = 0)
)
/* Do the actual split. The ISNULL/NULLIF combo handles the length for the final element when no delimiter is found. */
SELECT ROW_NUMBER() OVER(ORDER BY s.N1) AS ItemNumber,
SUBSTRING(@pString, s.N1, ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1), 0) - s.N1, 8000)) AS Item
FROM cteStart s;
GO
Thanks Scott. Looks great. I'll give it a whirl and compare consumption.