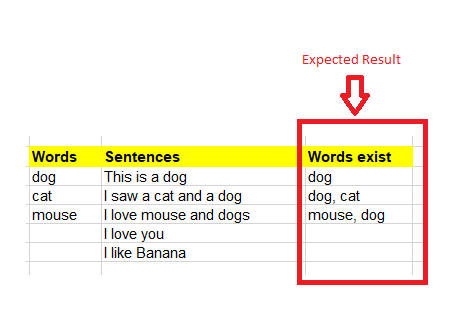
I would SPLIT the [Sentences] column into one-word-per-row and then JOIN that result to your [Words exist] column
Slight snag may be that a word may not be separated by spaces - e.g. hyphen, comma, etc., so you will have to take care of that.
I suggest you use Jeff Moden's Splitter Function as its probably the most efficient one out there.
yeah, that would be deadly I'm afraid ...
P.S. On tables where we want to do this (typically free-word search on names and Address, and product Descriptions etc.) we maintain a permanent table of split-words (i.e. change that any time the source Description is changed). We also have a dictionary of word-stems and alias words, so that we can "tune" the things that an end user might search for against the actual descriptions.
So for example Mice might be set up as an alias for Mouse - maybe Rat/Rats too? - ditto for plural-alias for Dogs and Cats
IF OBJECT_ID('tempdb..#Sentense', 'U') IS NOT NULL
DROP TABLE #Sentense;
CREATE TABLE #Sentense (
Sentense VARCHAR(1000) NOT NULL,
WordExist varchar(1000) NULL
);
INSERT #Sentense (Sentense) VALUES
('This is a dog'),
('I saw a cat and a dog'),
('I love mouse and dogs'),
('I love you'),
('I like bananna'),
('Cats and dogs living together');
IF OBJECT_ID('tempdb..#Word', 'U') IS NOT NULL
DROP TABLE #Word;
CREATE TABLE #Word (
Word VARCHAR(20) NOT NULL
);
INSERT #Word (Word) VALUES
('dog'), ('cat'), ('mouse');
--==============================================
UPDATE s SET
s.WordExist = STUFF(we.WordExist, 1, 2, '')
FROM
#Sentense s
CROSS APPLY (
SELECT
CONCAT(', ', w.Word)
FROM
#Word w
WHERE
s.Sentense LIKE '%' + w.Word + '%'
FOR XML PATH('')
) we (WordExist);
SELECT * FROM #Sentense s;
Hehehe ... yeah, I'm used to a decent spec too ... but in here I take a much broader assumption ....
Root-words much harder of course ... even "exact words" is reasonably hard, assuming that the delimiter cannot be guaranteed to be a space, or a set of easily handled characters.
But there again the underlying question might be actually about proprietary part numbers, or somesuch, which are inherently unique and won't give any false positives ...
I've been asked to do this sot of thing before and it's been my experience that those making the request don't tend to think through the ramifications of what they're asking for. In the end, depending on what's needed, this type of solution can be as simple as what I posted above to insanely complex "fuzzy logic" matching.
Until the OP comes back with some clarification, we really don't know, and I'm not going to waste my time coding a complex solution based on a , possible incorrect, hunch.
have emoji changed I wonder? I went looking for one, found loads of new ones (or so it seems to me) ... a Thumbs Up would have been nice to use ... but amongst the hundreds ... didn't find one of those at all.
I have to ask, how big are the sentences in bytes? For example, are they all <= 8000 bytes each? Also, what is the data-type of the column the sentences are in?