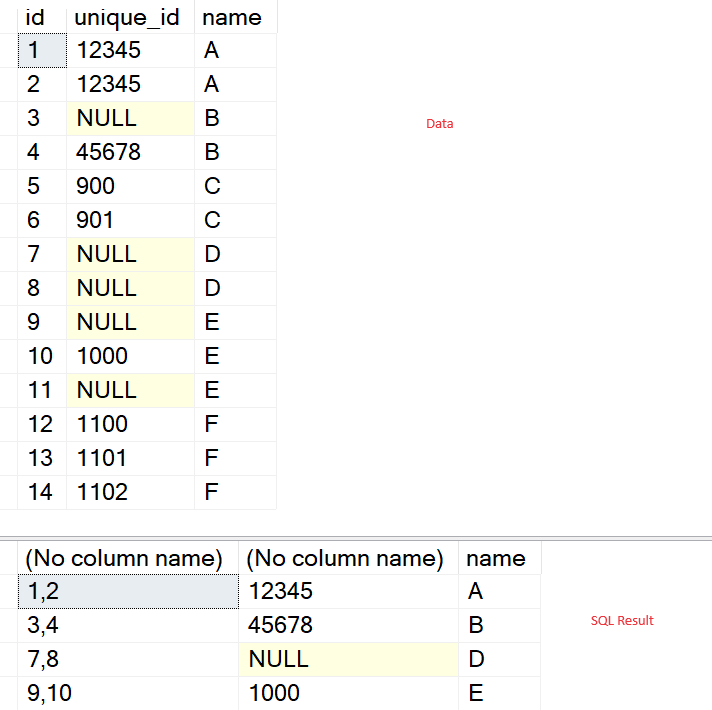
I've values in a table which are selected as duplicates if the name is same then the corresponding ids are included in a csv string column as below:
Original table:
create table #original(id int, unique_id varchar(500), name varchar(200))
insert into @original values
(1, '12345', 'A'), (2, '12345', 'A')
, (3, null, 'B'), (4, '45678', 'B')
, (5, '900', 'C'), (6, '901', 'C')
, (7, null, 'D'), (8, null, 'D')
, (9, null, 'E'), (10, '1000', 'E'), (11, null, 'E')
, (12, '1100', 'F'), (13, '1101', 'F), (14, '1102', 'F')
Person with name A, B are same but C isn't because unique id is different for C. A record is duplicate if the name is same AND unique id is there or null. When name is same but the unique ids are different then they aren't the same people.
I'm selecting the data as below: ;with cte as (select name from #original group by name having count(*) > 1)
I need to get the data as below:

C and F should be avoided as their unique_ids are different though names are same.
Thanks