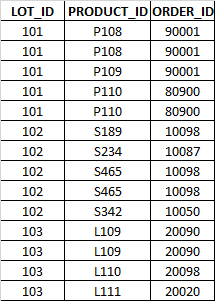
My table contains multiple lots (LOT_ID) and each lot contains multiple products(PRODUCT_ID) and there are multiple orders (ORDER_ID) under each Product. I would like to know the order ID’s which are repeated for multiple products for a given LOT
Order ID's ( 90001 & 10098 ) repeated twice for multiple products under the same LOT. so result set should only display the LOT_ID, PRODUCT_ID related to these orders
select b.* /* specify which fields you want to see */
from (select lot_id
,order_id
from yourtable
group by lot_id
,order_id
having count(*)>1
) as a
inner join yourtable as b
on b.lot_id=a.lot_id
and b.order_id=a.order_id
The only thing that different, is the 3rd and 4th s.no, which in my case is 4 and 6, in your case is 3 and 4.
Now if you look at your own sample data where lot_id=102 and order_id=10098, the s.no=4 and 6, so either your sample data is worng or your last comment are.