I have a query that returns the following results:-
Table1
Table2
Name1
Value1
Name1
Value2
Name1
Value3
Name2
Value1
Name2
Value2
What I'd like to return is:-
Table1
Table2
Name1
Value1
Value2
Value3
Name2
Value1
Value2
i.e. I only want to show one instance of column1 (Name) then show the next unique result in that column and replace the duplicate names with blanks/NULL
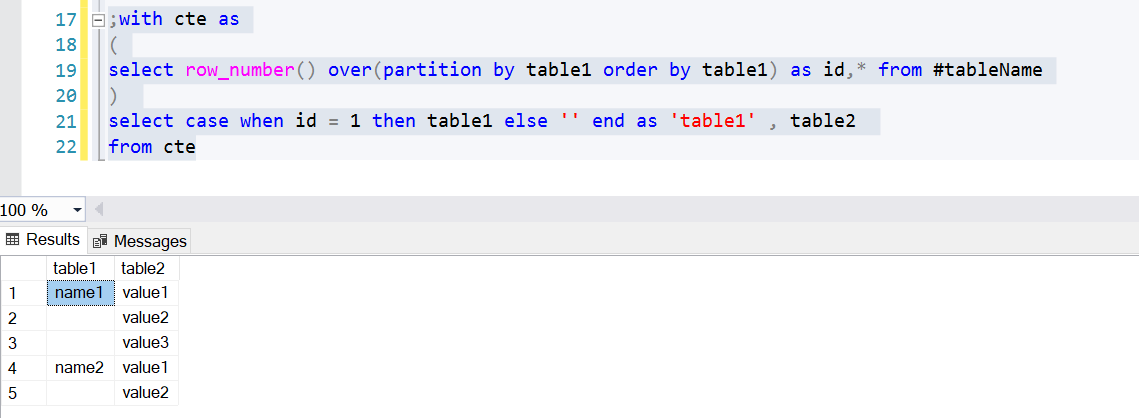
;with cte as
(
select row_number() over(partition by table1 order by table1) as id,* from #tableName
)
select case when id = 1 then table1 else '' end as 'table1' , table2
from cte
I'm going to be the unhelpful person who insists this is a presentation layer problem, not a something you should be solving in SQL.
That said, I've committed worse violations ;).
ROW_NUMBER() is a window function. v8553 is using it to assign row numbers, starting at 1, for each "table1" group. Then, he's dynamically filling in either the value from "table1" if the row number is 1 (the first of the partition), or an empty string if it's any other row from that partition.
It would help quite a bit if you also have a unique key field somewhere, like an ID that's different for each row. v8553's method can potentially return results in the wrong order otherwise.
If you need more specific help developing a specific solution to fit your needs, it would help if you could provide more detail about your actual source table structure as well as some representative example data.