Hi
I need to extract a string between the 2nd (of 3) set of square brackets in a field, as below -
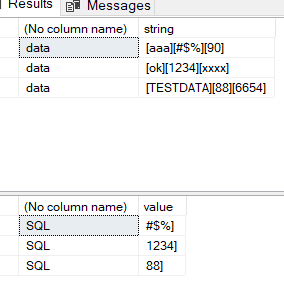
[TESTDATA][88][6654]
Therefore I need to extract '88' only (without the brackets). I can do this for the characters in the first or last set of brackets using CHARINDEX and REVERSE but have no idea how to tackle the middle set!
Just remember that PARSENAME() converts the results to the SYSNAME datatype, which is NVARCHAR(128) behind the scenes (in other words, the returns will be < 128 characters IF it doesn't fail first). If you use the result in a JOIN or a WHERE against a VARCHAR or CHAR column, it is guaranteed to ALWAYS do a non-clustered index scan at best or a clustered index scan at worst, because it has to convert the entire VARCHAR or CHAR column to NVARCHAR before it can to any comparisons.
Of course, if any of the "objects" between the brackets contain a period, that will also cause issues, possibly in the form of "silent truncation".
here's using string_split .. i know string_split is not reliable as its not consistent
question comes then why are you doing this ?
just exercising my Noodles ... other things cognition timing speed etc etc other stats of myself
for myself
create sample data script
select * into #abc
from
(
select '[TESTDATA][88][6654]' as string
union
select '[ok][1234][xxxx]'
union
select '[aaa][#$%][90]'
) a
select 'data',* from #abc
select
'SQL'
, value
from
(
SELECT
row_number() over(partition by string order by string ) as rn
, value
FROM
#abc
CROSS APPLY STRING_SPLIT(string, '[')
) a
where
a.rn =3
You could use a custom string splitter that includes the ordinal position - or you could stack CHARINDEX functions using cross apply:
Declare @testData varchar(100) = '[TESTDATA][88][6654]';
Select *
, SubData = substring(t.TestData, p1.pos, p2.pos - p1.pos)
From (Values (@testData)) As t(TestData) -- Mimic a table with a single column
Cross Apply (Values (charindex('[', t.TestData, 2) + 1)) As p1(pos) -- Position of 2nd [ in string assuming first [ is in position 1
Cross Apply (Values (charindex(']', t.TestData, p1.pos + 1))) As p2(pos) -- Position of 2nd ] in string
This assumes the column data will always have the brackets - if they may not then there is a way to deal with those depending on what the expected result would be.
Note: use a starting position of 2 in the first charindex allows us to skip the first open bracket to find the second. If that first open bracket exists somewhere else in a larger string - then we would need to find the first one - then use that position to find the second.
Any string parsing ninja script will come to eventually bite you in the tush.
Why is this data this way in the first place? Can you help us understand that? It is an unusual delimited data. What data is it representing?
declare @ninja table(stealthy varchar(150))
insert into @ninja
select '[TESTDATA][88][6654]'
select replace(v.Item,']','') as item, v.ItemNumber
from @ninja
cross apply DelimitedSplit8K(stealthy, '[') v
where v.ItemNumber = 3
All depends on the quality of the data. If the data is guaranteed to always be in a specific format - than any method will work. The problem is that we always see this kind of request - the data is not consistent.
There will be NULL's, empty strings, strings with only one set, strings with leading blanks, strings missing one or more delimiters - and other issues.
why am i doing this ? = tally table approach = much more reliable than string split "ordinal"
create table insert data script
-- Sample table
IF OBJECT_ID('dbo.SampleData', 'U') IS NOT NULL
DROP TABLE dbo.SampleData;
CREATE TABLE SampleData (
BracketString VARCHAR(50)
);
INSERT INTO SampleData (BracketString)
VALUES
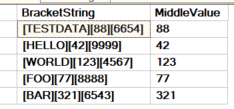
('[TESTDATA][88][6654]'),
('[HELLO][42][9999]'),
('[WORLD][123][4567]'),
('[FOO][77][8888]'),
('[BAR][321][6543]');
-- Tally table approach
;WITH Tally AS (
SELECT TOP (100) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM sys.objects
)
SELECT s.BracketString, x.Item AS MiddleValue
FROM SampleData s
CROSS APPLY (
SELECT Item
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY N) AS Pos,
SUBSTRING(s.BracketString, N+1, CHARINDEX(']', s.BracketString, N) - N - 1) AS Item
FROM Tally
WHERE SUBSTRING(s.BracketString, N, 1) = '['
) t
WHERE Pos = 2
) x;