Hi All.
I found on-line query how to eliminate duplicates using UNION ALL
SELECT * FROM mytable WHERE a=X UNION ALL SELECT * FROM mytable WHERE b=Y AND a!=X
Can someone explain that query on example with real data?
Thanks
Hi All.
I found on-line query how to eliminate duplicates using UNION ALL
SELECT * FROM mytable WHERE a=X UNION ALL SELECT * FROM mytable WHERE b=Y AND a!=X
Can someone explain that query on example with real data?
Thanks
select 'eugz' as 'Using union' union
select 'eugz'
select 'eugz' as 'Using union ALL' union all
select 'eugz'
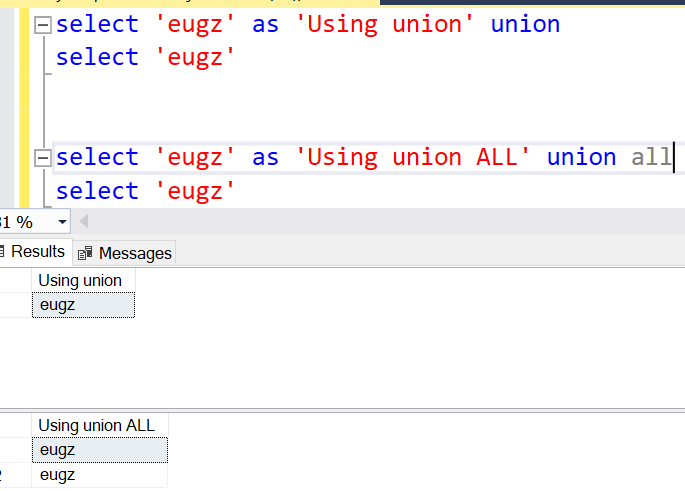
UNION ALL does not eliminate duplicates, it actually allows for duplicate as above
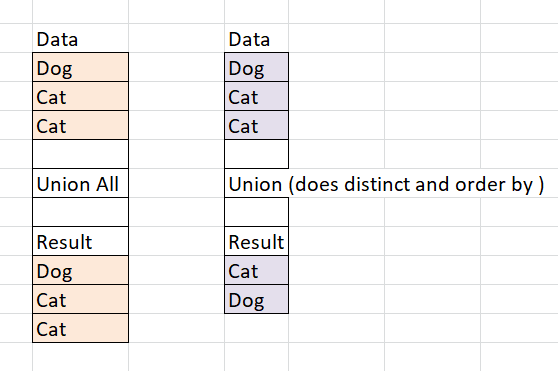
hi
hope this helps .. excel way of showing
Thanks for replay.
I understand if to use UNION duplicated will be eliminated and UNION ALL works faster but it don't eliminate duplicates. My question was. How to use UNION ALL and eliminate duplicates? How figure out the query:
SELECT * FROM mytable WHERE a=X UNION ALL SELECT * FROM mytable WHERE b=Y AND a!=X
with real data.
Thanks.
UNION ALL doesn't necessarily work faster - it depends on the queries in each portion of the statement. If you need non-duplicated results then UNION might be the better option - but it depends.
If you can write each query to return distinct rows - and those queries perform better than using UNION then that is an option that can be used.
The query you posted simply select all rows (and all columns using * which is not recommended) where a = X in the first part - then selects all rows from the same table where b = Y and a <> X. It could also be rewritten to as WHERE a <> X...
This does not guarantee that no duplicates will be returned - because each individual query could return duplicates within their own set.
Hi jeffw8713. Thanks for reply.
So. Bill Karwin's post on this link:
https://stackoverflow.com/questions/41729082/sql-union-all-to-eliminate-duplicates
is incorrect?
Thanks
Partially - the problem is the assumption that either query in the UNION ALL returns a distinct set. Given this simple example:
Declare @testTable Table (a int, b int);
Insert Into @testTable (a, b)
Values (1, 1)
, (1, 2)
, (2, 1)
, (2, 2)
, (1, 1)
, (2, 2);
Declare @x int = 1
, @y int = 2;
Select * From @testTable Where a = @x
Union All
Select * From @testTable Where a <> @x;
Select * From @testTable
Union
Select * From @testTable;
You would expect the results to be the same - but they are not...because there are duplicates returned by each query. So what we see in the UNION ALL is 6 rows including the duplicates - and in the UNION those duplicates are removed and we only get 4 rows.
To make the UNION ALL work correctly - you would need to do the following:
Select Distinct * From @testTable Where a = @x
Union All
Select Distinct * From @testTable Where a <> @x;
But - now you have 2 sorts - one for each distinct operation that is performed prior to the UNION, whereas the UNION would have a single sort after the union of the data. Which performs better - it depends...
Just write the query the natural way, it's difficult to imagine a table structure that would make the query more efficient as separate UNION ALL queries given the specific conditions. So, to answer your follow-up q, yes, the linked-to article is incorrect.
SELECT *
FROM dbo.mytable
WHERE a=X OR b=YWhen I first read the question, I remembered "SELECT DISTINCT", as well.
The question actually came from a site where people are asked to submit possible interview questions. A lot of times, interviewers will ask off the wall questions to show how smart they think they are instead of asking questions to show how smart the candidate is. This question is no exception and the extremely low quality of the answer also says the person that wrote the question either doesn't know how to "teach" or is too arrogant to think they may have done it improperly.
Here's the link to the site with the questions. And, if someone were to ask me a question like that during an interview, I'd seriously be thinking as to whether or not I'd actually want to work with such people.
There's an art to proper interview questions... that question fails on a whole lot of fronts and the answer is even worse because it actually teaches nothing except that I wouldn't want to work for such a company even if I needed the job.
My favorite q for experienced SQL developers is (comes from a real-life situation, but obviously simplified):
Given a table with: ( student_id, test_id, score )
and assuming 1 to 3 test scores are present per student, write a single query (no cte, subquery, etc.) that lists:
student_id,
average_score,
high_score (a single score would go here),
middle score (NULL if no middle score),
low score (NULL if only a single score).
It's amazing the different types of answers that you get, esp. from people who claimed to be "really good with SQL".
Heh... Since you didn't define the datatype for score, I see people forgetting about integer math for the average. Since you say you use it during interviews, I don't want to give up too much and certainly not post an answer here for it but does your preferred answer use the simple difference of aggregates?
I can also see why people claiming to be "really good" might have a problem with that... they forget plain ol' common logic and some basic arithmetic especially when it comes to that middle score. 
Yes.
Yeah, the middle score and the avg score both cause issues for many people. I hadn't considered it being a math issue, maybe I need to switch it to use strings, since some people are phobic about math.
The string thing might be a good one to keep separate. My personal opinion is that if you're going to be a DBA or Developer, you actually do need to know how to do a bit of simple subtraction and have the little tiny little bit of logic to see that's one way of doing it.
I don't necessarily expect them to get to the avg ... and it's informative to see how they deal with that.