@Barkas ,
Heh... too funny how life sometimes works. 24 years ago, the very first question I had on my very first project was nearly identical. I couldn't get an answer from the instructor that I was taking my one and only SQL training course from and the forum I found way back then (Belution.com... long dead now) also had a lot of similar questions. I even gave MS a call... they all gave me the same technically correct answer of "If you had done things the right way, you wouldn't have any dupes".
The problem was that I didn't create the data... it came in a file and I was the one that had to figure out what the dupes were and delete all but one row of duplicated rows and so their well intended technically correct answer was totally useless to me.
Your problem specifically says "Duplicates two columns and two rows" implying that the data will only ever have two rows for dupes and that there will ALWAYS be two dupes. You shouldn't actually count on that. There could be more than two dupes and you could end up with rows with no dupes.
And, you don't want to have a whole batch of rows get rejected just because 1 row fails some check constraint.
With that in mind, you need to make your code a whole lot more bullet proof so if/when that changes someday, your code will auto-magically handle it all without missing a beat.
With such anomalies in mind, let's add some rows to your original test data (and thank you for posting that!)...
DROP TABLE IF EXISTS #TEST;
CREATE TABLE #TEST
(
ID INT NOT NULL
,VAL_A VARCHAR(10) NOT NULL
,VAL_B VARCHAR(10) NOT NULL
)
;
INSERT INTO #TEST
(ID, VAL_A, VAL_B)
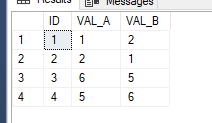
VALUES (1,1,2),(2,2,1),(3,6,5),(4,5,6) --Original Test Data
,(5,7,8),(6,8,7),(7,7,8) --Triplicate
,(8,9,1) --No Dupe
;
SELECT * FROM #TEST
;
Very fortunately, the code to do the bullet-proofing is the same code to solve your immediate problem with its current limited requirements. Here's the code to solve your problem and future problems. It DOES assume that you want to keep the one duplicate row that has the lowest ID. You can certainly and very easily flip that around to keep the one duplicate row that has the highest but I'm sure you'll have no problem figuring that out if that's what you need to do.
WITH cteSortVal AS
(
SELECT ID
,VAL_A
,VAL_B
,Dupe# = ROW_NUMBER() OVER (PARTITION BY IIF(VAL_A <= VAL_B, VAL_A, VAL_B)
, IIF(VAL_A <= VAL_B, VAL_B, VAL_A)
ORDER BY ID)
FROM #Test
)
DELETE FROM cteSortVal
WHERE Dupe# > 1
;
SELECT *
FROM #Test
;
Also notice the trick of deleting from the original CTE, which deletes the rows from the underlying table.