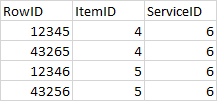
I have a table that stores relationships between Items and services. I ran a query that caused near duplicate rows (PK saved the day) and need to delete those rows (This is in my development environment and this is just to make my life easier and to learn).
The rows look like this:
I have a unique PK, but have duplicate relations between ItemID and ServiceID and would like to delete the row with the highest PK value that is a dupe.
;with cte as
(
select ROW_NUMBER() over(partition by itemId, ServiceId
order by rowId desc) as RN
from
YourTable
)
delete cte where RN = 1;
Even if you have more than two rows where itemId and serviceId are identical, it will delete only one row (which seems like is what you wanted).
One technique I use when I have to delete/insert/update, and want to be absolutely sure is to open a transaction, do the insert/update/delete, and then look at the number of rows affected, or do a select to make sure the operation did what I wanted. If it did, then i run commit, if not I run rollback. On hot tables, make sure you minimize the time the transaction is open.
It sounds to me like the OP doesn't want any dup rows, so I would code it to delete all dups:
;WITH cte_dups AS (
SELECT RowID, ROW_NUMBER() OVER (PARTITION BY ItemID, ServiceID ORDER BY RowID) AS row_num
FROM dbo.table_name
)
DELETE FROM cte_dups WHERE row_num > 1
@James: Btw, wouldn't your code delete even those that didn't have dups?
Edit: If for some reason you did want to delete only a single dup, you would use:
"WHERE row_num = 2"
Thank you so much guys! Scott, you're correct, I would rather have no duplicates. I will now do some learning on what is going on in these queries to better my skills!