Does anyone do Table Index Rebuilds based on the avg_page_space_used_in_percent (internal fragmentation) rather than avg_fragmentation_in_percent (external fragmentation)?
I looked in the Ola Halengren job for this and it chooses what to do based on external fragmentation.
But I think Internal Fragmentation is more of an issue. With internal fragmentation, SQL Server will spend more time bringing pages from Disk to cache since there are more pages due to the unused space within pages. In addition, Internal Fragmentation takes up more space in both the cache and on Disk. Where as External Fragmentation just means the pages may not be adjacent to each other but with SSD, getting the pages is quick. If Data is in the cache already, External fragmentation isn't a harm anyway.
I don't think I've heard of it referred to as "internal fragmentation" before. I don't think it's particularly accurate either, a page is a page. SQL Server's rowstore format is based on 8K pages, that's the smallest unit of memory buffering it does. If your data doesn't fill an entire page, that's lower density, but within the page itself there's no real concept of fragmentation.
Most people using Ola's procedures stick with the defaults, which are reasonable and I believe aligned with Microsoft's recommendation.
Where density helps you is reading fewer pages to satisfy all the rows the query would return, as you've already mentioned. That's controlled by fillfactor, or rebuilding/reorganizing low density pages to consolidate to as few pages as necessary. There's also index compression, but that requires a rebuild.
I can't say I agree with "if data is in cache already, external fragmentation isn't a harm". There's no real benefit either. There's also the I/O extent, which is 8 contiguous pages in a SQL Server file:
Whether a page is in cache or not, there's additional management of extents, allocations, PFS etc., that is amplified if data is stored in non-contiguous disk segments. This doesn't go away just because SSDs are substantially faster than spinning disks.
Another consideration is not just keeping data in cache, but also which kind of cache. RAM is substantially slower than L1/L2/L3 access, and however much you can reduce RAM usage, it amplifies tremendously if that translates to CPU cache reuse. This especially shines with columnstore, which is a highly optimized memory structure that also fits within 8K pages, but using a completely different access pattern that would suffer tremendously if CPU caches had to be constantly flushed/refreshed from RAM.
I think that using the terms of "Internal" and "External" to describe fragmentation is wrong because there is a physical overlap between the two. I've taken to (especially in the last couple of years) using only "Logical Fragmentation" and "Page Density".
On that note, I've found that there are a few basic "Patterns of Fragmentation" and I adjust between looking for "Logical Fragmentation" and "Page Density" for both with the clear understanding that, although many have said "Logical Fragmentation CAN be a performance problem", I have found that most people don't actually know one way or the other because they haven't actually tested. I've found that it can sometimes make a little difference but it's small enough to make the cure much worse that the problem.
With that being said, most of what I do is simple "space recovery" and I try to NOT do that to every index that needs it in a "single night". I also do some "fragmentation prevention" where I can and that involves looking at both "Logical Fragmentation" and "Page Density", especially for "evenly distributed" index types such as Random GUIDs (I prevent fragmentation for MONTHS there) and similar (Type 1, for me) indexes and only "Page Density" for "Exploded Broomtip" (Type 97, for me) indexes because nothing will prevent the fragmentation for those (especially lowering the Fill Factor, in this case).
Here's a 'tube where I use Random GUIDs to destroy a few myths about fragmentation and lay waste to what used to be the supposed "Best Practices" until 20 April 2021. Note that, despite the title (which I'm going to change for future 'tubes, articles, and presentations because people come to the wrong conclusion based on the title), the 'tube below is NOT just about Random GUIDs and it's NOT making the suggestion that people change their indexes to Random GUIDs. I used Random GUIDs because they're the proverbial "Poster Child" for fragmentation and I use them only to demonstrate that humans have created the problems.
Here's the link and be advised that there are some sudden and loud "commercials" at the 15:00, 30:15, and 45:25. The advertisements are important to help support this event but I wanted to let you know that they're sudden and they're loud! They WILL lift your headset!
Because SQL Server doesn't have to go all over the place on disk for a scan operation involving a Fragmented Index if the Data is in the Cache - it doesn't need to fetch it from Disk.
Will Fragmented Indexes still be fragmented in cache - or does SQL Server put them in the cache in the correct order? Similarly, can an unfragmented index be fragmented in cache? I think it could be. But this would probably be not much of a performance concern since the Data is in Cache.
SQL Server Internal Fragmentation is caused by pages that have too much free space
I don't think records inside a page can become unorded - or can they? Anyways they have empty space.
Here's the problem with what a lot of people have when they talk about fragmentation... it's ALL talk and with no proof, in most cases.
To be a bit blunt, there are way too many people out there that say things like Brady did. To quote from his article
"So is fragmentation an issue? I believe it is."
His belief has no grounds other than what he thinks and a lot of that is based on what other people have only surmised (definition of that word is "To make a judgment about (something) without sufficient evidence; guess." American Heritage Dictionary Entry: surmise ).
If you haven't seen the 'tube I posted the link to above, what is the actual cause of indexes based on Random GUIDs fragmenting so rapidly? Almost everyone in the world says "because it's a random value". The truth is, having such an evenly distributed random value is actually a huge fragmentation preventative and is the epitome of how people think most indexes should operate. Unlike others making claims about indexes, I prove that with code that I demo in my presentation.
The real cause is the incorrect index maintenance that is being done and the primary cause there is the use of REORGANIZE, which doesn't work the way people think it works because of the unfortunate wording used about it using the Fill Factor. And, yeah, I prove that with demonstrabble code, as well,
Like I say at the beginning of the 'tube, send me an email at the email address I included int he presentation and I'll send you a copy of the code (and that's ALL I'll use your email for because I treat people like I'd like to be treated).
I'll also tell you the I've identified 7 different fragmentation patterns. I'm still looking for others and I'll eventually get to writing a series of articles on all of this...
Also, try the following experiment...
Just before your index maintenance, measure the resources and duration of the related workload.
Immediately after that, do your index maintenance and then measure the same workload for resources and duration.
Wait until the next time you need to do the same index maintenance and repeat step 1 but NOT step 2. Instead, just rebuild statistics and measure the work load again.
Did you find a difference between the measurements after step 1, step 2, and step 3 and, if so, are they large enough to TRULY make a difference?
I'd tell you about how I went for 4 years without doing any index maintenance on my main production box but that we require me to make a claim that I have no proof for because I didn't believe I'd ever need to prove it and so didn't do any screen shots, etc.
There is no guarantee that the rows are in any order within a page. That's why the slot array is there. To find a row (according to Paul Randal), the system does a binary search.
Ya, we get a lot of stuff like Performance, slow, so and so checked and there's fragmentation...
Then I would look and the Fragmentation was on a very small table, so not relevant. On a table where Microsoft doesn't even recommend defrag since the table is so small.
This is a very interesting thread. I'm struggling with index maintenance in a world that is 24x7 AlwaysOn and SSDs. We turned off index maintenance years ago on some big databases and have never turned it back on. I haven't seen any high-level performance issues.
Would performance be better with maintenance? Maybe? Probably a little? How would I know? Realistically there are SO MANY things going on it is difficult to isolate a "load" that I can test against.
Where would you look for to say, "This slowdown is because of fragmented indexes" ?
More page reads, I guess. But it's not going to be 10x the optimal page reads...
and I've already committed so many other sins that probably need looking into first...
What's really funny is that most of the "experts" out there only talk about two forms of fragmentation... Internal (page density) and External (Logical Fragmentation) with Logical Fragmentation being thought of as the most important because it's usually the cause (page splits) Page Density issues.
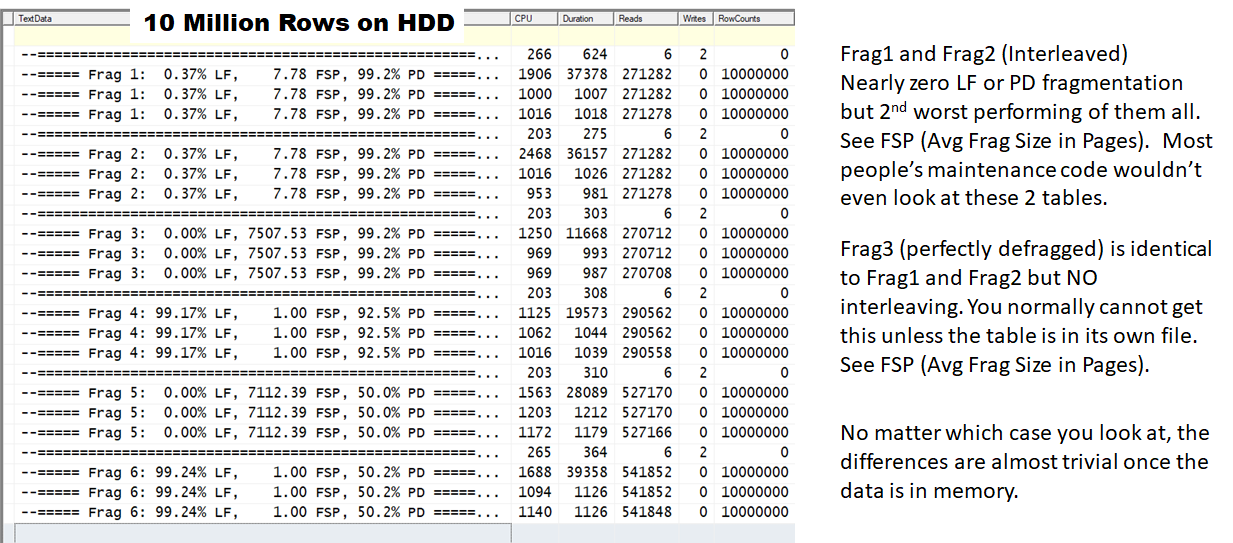
I did an experiment about 4 or 5 years ago with a 3rd type of fragmentation that does not necessarily show up as Logical Fragmentation or Page Density problems. It's funny that this is coming up today because I had the need to rerun that experiment again last night. You're old school like me and so you'll instantly know what I mean when I say "Interleaving" of indexes, which can be recognized by "Average Fragment Size in Pages".
As to your question, the only way to know, for sure, if a slowdown is because of a fragmented index is to first rebuild the statistics and try again. If that doesn't fix the slowdown, REBUILD it and try again. DO NOT REORGANIZE IT. See the 'tube I attached for all the reasons why.
You are absolutely correct and I've edited the post so that no one makes the mistake of doing a rebuild first. I'll blame not being sufficiently caffeinated for making the error that you thankfully have caught.
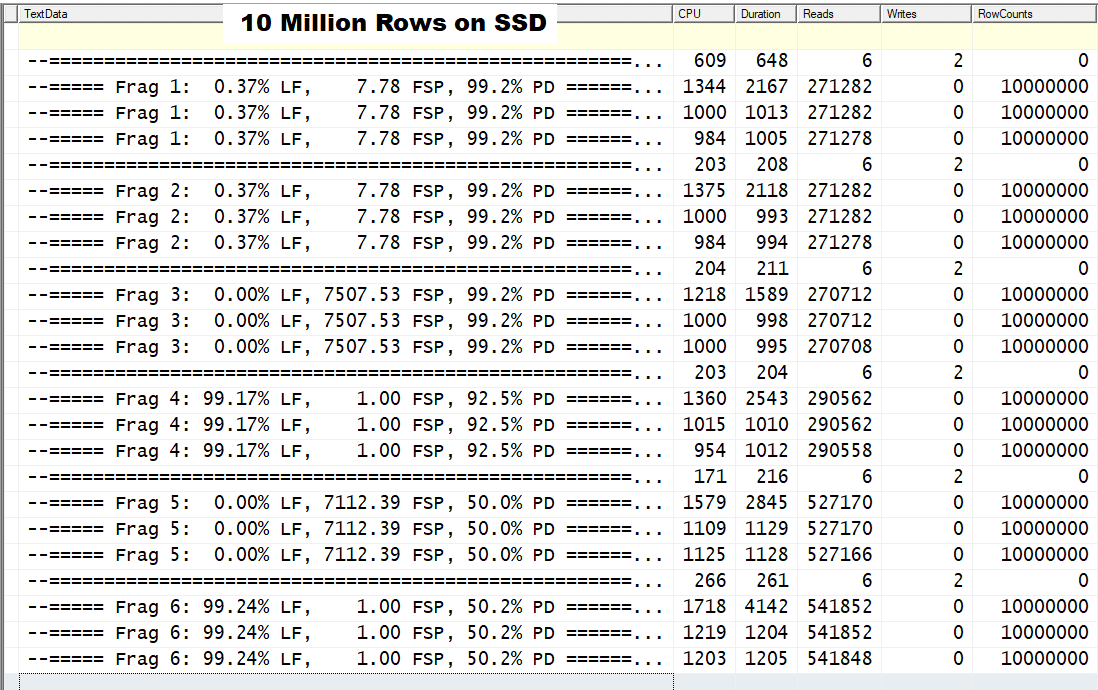
Actually, it wasn't an easy answer "back then" either. Like I said, I've been doing experiments on my laptop, which has both a high performance HDD and SSD.
Here are the results from ordered full tables scans on 6 different tables on a fast hard drive.
Here are the stats for the same tables on SSDs. Logical fragmentation and interleaving just about don't matter at all. The only thing that really matters is Page Density for conservation of RAM but even that doesn't matter much any more until you get MUCH larger (These tables are quite small nowadays). It will always matter for "storage" and backup size, though.
And that is the real key - don't perform index maintenance to address performance issues.
Back in the olden days - on non-SSD drives, contiguous space was important for performance. But only when reading contiguous pages of data since the read/write heads would not have to move a lot.
Enterprise level SAN's eliminated that issue because a file is now spread across hundreds of drives.
However, storage, memory and IO are still very much affected by fragmentation. Specifically - page density where you could be wasting half your memory and storage and empty space and requiring double or more IOs to get the same amount of data.
Even worse - since SQL Server and Windows may issue a 64K read you could end up reading 8 pages for data that exists on a single page where the other 7 pages have no useful data for current processing.
Careful now... I CAN show you at least one exception. If you don't perform the right kind of index maintenance at the right time on Random GUID keyed indexes, You end up with some pretty nasty page splits and THAT IS a performance issue that DOES need to be fixed.