Hi, I use a proprietary environmental chemistry database software. I don't have access to SQL or writing queries in this software. The software comes with a series of preset queries with some selections availilble. For example, the "Analytical Results" query will always return a bunch of preset columns from a variety of different tables within the schema, but when selecting the query, i do have some options, such as selecting date ranges, or locations if i'd like.
The query also does have an additional field one can use before returning the results of the query which allows the user to write some basic T-SQL code to produce some custom columns. For example (looking at my table), i can use T-SQL to concatinate the start and end depths in it's own custom column called "depth_range".
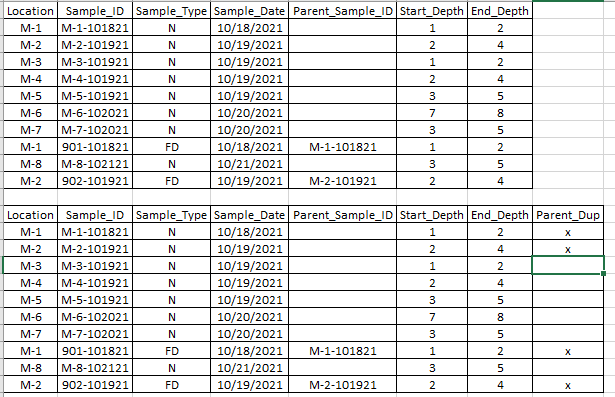
Looking at my table, there are duplicate samples (sample_type = FD) which are samples that are collected as a duplicate of one of the (sample_type = N) samples. The sample the duplicates are associated with is placed in the parent_sample_id column.
There are many crosstab tables we produce that just compares the "N" samples to it's associated "FD" sample. There is no good way with the sofware to target just these specific samples and the crosstabs requires post-processing in excel.
I'd like to be able to make a custom column "parent_dup" with an 'x' flag denoting all the samples that are FDs and their corresponding parent sample.
snippet of the standard report and snippet of report with custom field:
Thanks in advance