Hey guys,
I'm looking for a solution to this problem.
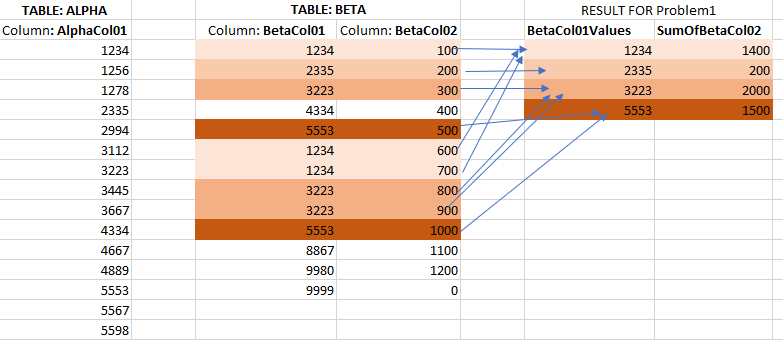
I have 2 tables: ALPHA and BETA.
In ALPHA: I have a column called "AlphaCol01"
In BETA: I have 2 columns called "BetaCol01" and "BetaCol02"
So it's the following format with these values (image attached below):
TABLE: ALPHA
Column: AlphaCol01
Values: 1234, 1256, 1278, 2335, 2994, 3112, 3223, 3445, 3667, 4334, 4667, 4889, 5553, 5567, 5598
TABLE: BETA
Column: BetaCol01
Values: 1234, 2335, 3223, 4334, 5553, 1234, 1234, 3223, 3223, 5553, 8867, 9980, 9999
Column2: BetaCol02
Values: 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 0
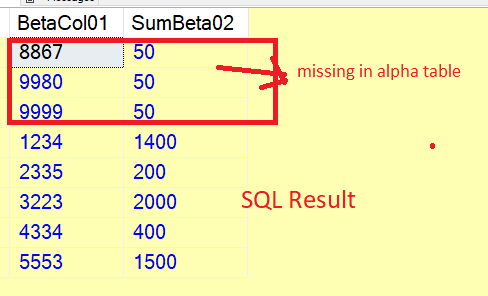
And what I'd like to get, is:
-
If we're joining BETA table's "BetaCol01" column to ALPHA table's "AlphaCol01", I'd like to get a list of values grouped by "BetaCol02" where the list contains all the values, summed and then grouped by BetaCol02, where the value of BetaCol02 can be found in ALPHA table's AlphaCol01 column.
So this result, basically:
-
I'd like to get a number (in percentage) to see that how many distinct BetaCol01 values can be found in AlphaCol01 column. So in the original example, we have 8 distinct values in BetaCol01, and out of those 8, 4 of them doesn't have any matches for AlphaCol01, so the result is 50%.
Thank you for your help in advance!