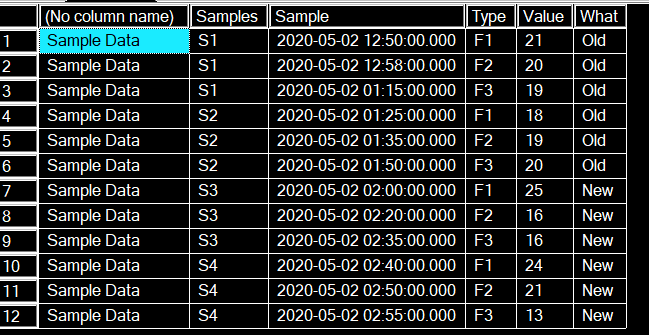
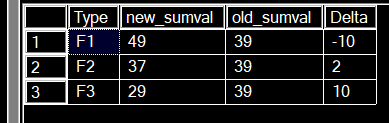
sample_data
drop table #samples
go
create table #samples
(
sample varchar(100) NOT NULL,
sample_datetime datetime NOT NULL,
type char(2) NOT NULL,
value decimal(9, 2) NOT NULL,
delta_mean_status tinyint NOT NULL DEFAULT 0,
delta_mean decimal(9, 2) NULL
)
go
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S1','05/2/2020 12:50','F1',21,0
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S1','05/2/2020 12:58','F2',20,0
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S1','05/2/2020 1:15' ,'F3',19,0
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S2','05/2/2020 1:25' ,'F1',18,0
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S2','05/2/2020 1:35' ,'F2',19,0
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S2','05/2/2020 1:50' ,'F3',20,0
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S3','05/2/2020 2:00' ,'F1',25,1
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S3','05/2/2020 2:20' ,'F2',16,1
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S3','05/2/2020 2:35' ,'F3',16,1
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S4','05/2/2020 2:40','F1',24,1
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S4','05/2/2020 2:50','F2',21,1
insert into #samples (sample, sample_datetime, type, value, delta_mean_status) select 'S4','05/2/2020 2:55','F3',13,1