Hello everyone!
I am almost sure that someone already made a similar topic but I couldn't formulate exactly what I want to find it so I want to ask a question. Maybe it will help somebody too.
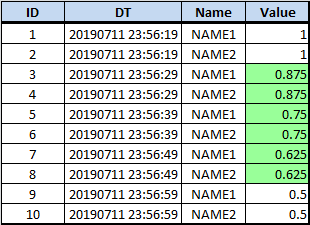
Let's say that we have some test data that looking like this:
Is there any way to replace null values with for example calculated average of previous and next not-NULL values? So for the third and fourht rows the VAL value will be (1 + 0.5) / 2 = 0.75; for the fifth and sixth rows it will be (0.75 + 0.5) / 2 = 0.625, etc.
Creating table code is shown below.
DECLARE @testTable TABLE (
ID INT IDENTITY(1, 1) NOT NULL,
DT DATETIME NOT NULL,
NAME VARCHAR(10) NULL,
VAL FLOAT NULL
PRIMARY KEY (ID, DT)
);
INSERT INTO @testTable(DT, NAME, VAL)
VALUES
('2019-07-11T23:56:19.000', 'NAME1', 1),
('2019-07-11T23:56:19.000', 'NAME2', 1),
('2019-07-11 23:56:29.000', 'NAME1', NULL),
('2019-07-11 23:56:29.000', 'NAME2', NULL),
('2019-07-11 23:56:39.000', 'NAME1', NULL),
('2019-07-11 23:56:39.000', 'NAME2', NULL),
('2019-07-11 23:56:49.000', 'NAME1', NULL),
('2019-07-11 23:56:49.000', 'NAME2', NULL),
('2019-07-11 23:56:59.000', 'NAME1', 0.5),
('2019-07-11 23:56:59.000', 'NAME2', 0.5);
SELECT *
FROM @testTable
ORDER BY DT, NAME
Any advice will be appreciated.
Thanks in advance!
Ok... Lead or Lag... let's see you good folks that are recommending those write the code to solve the OPs problem (especially since the OP provided readily consumable data).
So, just to be sure, the following is what you want to return, correct? In other words, a true smoothed linear interpolation? Also, there is some functionality that became available at SQL Server 2012. Are you using at least SQL Server 2012 or something earlier?
Jeff, if I am interpreting the question correctly, OP is looking for a modified recursive type of interpolation. If that indeed is what is desired, I can't think of a way to do that in a set-based query.
I agree with you on what we both think the OP wants but I like to make sure. I also need to hear back from the OP about which release of SQL Server he's using.
As for a set-based solution? It's actually pretty easy if you consider "Pseudo-Cursor" solutions that look set-based and I'm not talking about rCTEs (which are not actually "Pseudo-Cursors").
I'm pretty sure that James knows what I'm talking about but, if you're reading this and you don't know what a "Pseudo-Cursor" is, almost all SELECTs are "Pseudo-Cursors" because, behind the scenes, SELECTs are pretty much like any other file system reader... find a row, read the row, do something with the row, test to see if we're done, if we're not... loop back and do it again. Behind the scenes, they're a high speed machine language loop and since they also read one row at a time, they're also known as a "cursor". To distinguish them from the Cursor keyword, I refer to them as a "Pseudo-Cursor" (a phrase first coined by R. Barry, Young on SQLServerCentral.com).
@Captain11...
Hey there, Olga... just waiting on some responses from you on the two questions I have for you in my 2nd post on this thread. Once I have answers to those questions, I'll be able to hammer something out for you after work tonight.
That I got from the description the OP posted although I do agree... it's a bit of an assumption on my part but a good assumption even if I do say so myself. My intention was to expand the test data quite a bit and was going to include something similar to what your comments stated plus a couple of more use cases, just to be sure.
Hello, @JeffModen!
So sorry for a long reply: there was some issues at work :c
Can you please explain how you get such results? Can this be done with SQL? It may be exactly what I need since, judging by the @JamesK's answer, my original result is hard or even impossible to get.
@yosiasz , hello!
I define a previous (and the next) row by the date.
What about the gaps - can you please explain about it a bit? I think I didn't exactly understand what you mean. Sorry about that, I'm still new in SQL.
If you've ever heard of a "Tally Table" in SQL Server then, indirectly, you already know me because I'm the guy that wrote the article about how "Numbers Tables" work where I said that that I didn't like that name and changed it to "Tally Table", instead, because "To Tally" means, "To Count".
James is correct in that this problem of yours does require a loop of sorts. Something that I rant about a bit is that in every computer programming course there is, they teach people how to loop in all of those languages but they (MS official classes, most college professors, and a wealth of blog and article writers) simply don't teach the right way to do it in SQL Server. Oh sure... they teach While Loops (RBAR) and Recursive CTEs (Hidden RBAR), but those are usually NOT the right way to count.
Of course, the reason why I rant about how to count in SQL Server is because ordered counting in SQL Server is the essence to solving most "unsolvable" problems in T-SQL without RBAR or having to resort to CLRs or other nasty solutions. This is especially true since they came out with LEAD and LAG are now available (since 2012) and they finally fixed a lot of the broken or crippled Windowing Functions (also done in 2012).
So, with that, here's your original test data... I changed the test table to a session persistent temporary table so people could "play" with sections of the code I wrote as a possible non-RBAR solution. I also changed the casing in the code because I have a natural hate for all upper or lower case object and column names. Heh... if you have a case sensitive server, my apologies but I have little sympathy.
CREATE TABLE #TestTable
(
ID INT IDENTITY(1,1) NOT NULL
,DT DATETIME NOT NULL
,NAME VARCHAR(10) NOT NULL
,VAL FLOAT NULL
,PRIMARY KEY (ID, DT)
)
;
INSERT INTO #TestTable
(DT, NAME, VAL)
VALUES ('2019-07-11 23:56:19.000','NAME1',1)
,('2019-07-11 23:56:19.000','NAME2',1)
,('2019-07-11 23:56:29.000','NAME1',NULL)
,('2019-07-11 23:56:29.000','NAME2',NULL)
,('2019-07-11 23:56:39.000','NAME1',NULL)
,('2019-07-11 23:56:39.000','NAME2',NULL)
,('2019-07-11 23:56:49.000','NAME1',NULL)
,('2019-07-11 23:56:49.000','NAME2',NULL)
,('2019-07-11 23:56:59.000','NAME1',0.5)
,('2019-07-11 23:56:59.000','NAME2',0.5)
;
SELECT *
FROM #TestTable
ORDER BY DT, NAME
;
Here's my proposed "set based" solution. And now you see why I say that "Understanding how to count is one of the more important programming techniques you could ever learn".
WITH
cteGroup AS
(--==== This assigns a group number to each row. It works because COUNT does NOT count NULLs.
SELECT ID
,DT
,Name
,Val
,GrpNum = COUNT(Val) OVER (ORDER BY Name,DT)
FROM #TestTable
)
,cteOffset AS
(--===== This calculates the offsets we need to look forward to the next non-null value,
-- which is also the first row of the next group. It also counts the number of the
-- rows in the group to be used as the divisor to calculate the interpolation constant
-- of each group. The multiplier for the interpolation constant is the CurrRowOffset.
-- The NextRowOffset is where the next non-null value lives. The CurGrpVal is what the
-- current "smeared down" VAL is.
SELECT ID
,DT
,Name
,Val
,GrpNum
,CurGrpVal = MAX(Val) OVER (PARTITION BY GrpNum)
,NextRowOffset = ROW_NUMBER() OVER (PARTITION BY GrpNum ORDER BY Name,DT DESC)
,CurrRowOffset = ROW_NUMBER() OVER (PARTITION BY GrpNum ORDER BY Name,DT) - 1
,RowsInGroup = COUNT(*) OVER (PARTITION BY GrpNum)
FROM cteGroup
)--===== This does the return and the calculation of the interpolated values.
-- Comment out what you don't want to see. I left everything in so you can see what's happening.
SELECT ID
,DT
,Name
,Val
,GrpNum
,CurGrpVal
,NextRowOffset
,CurrRowOffset
,RowsInGroup
,InterpolatedVal = CASE
WHEN Val IS NOT NULL THEN Val
ELSE CurGrpVal
+ (
(LEAD(Val, NextRowOffset, CurGrpVal) OVER (ORDER BY Name,DT) - CurGrpVal)
* (CurrRowOffset*1.0 / RowsInGroup)
)
END
FROM cteOffset
ORDER BY ID
;
If you really want to study what's happening in the code, change that last ORDER BY in the code to...
I was going to write a recursive CTE and While Loop method to compare it against for performance because RBAR can sometimes win out (strange but true). There are two problems with me doing that though... One is that I'm out of time for the evening and, two, the reason why I say that is my poor ol' head can't think of a decent way to do it in either an rCTE or While Loop tonight.
If you good folks would like to write either a Recursive CTE or While Loop to compare this against, I'd be happy to do the performance testing/comparison. Right now, some informal testing shows that I can dump the solution output of having 4 names, each with 100,000 rows and 1 non-null value every thousand rows, to a temp table in about 6 seconds. With all the parallelism that went on, I'm thinking that's a bit slow (no... I'm not being sarcastic or ironic here... it seems like it should/could be faster) and would love to double check it against someones rCTE or While Loop.
Thanks for the help if anyone decides to help out with that on this interesting thread.