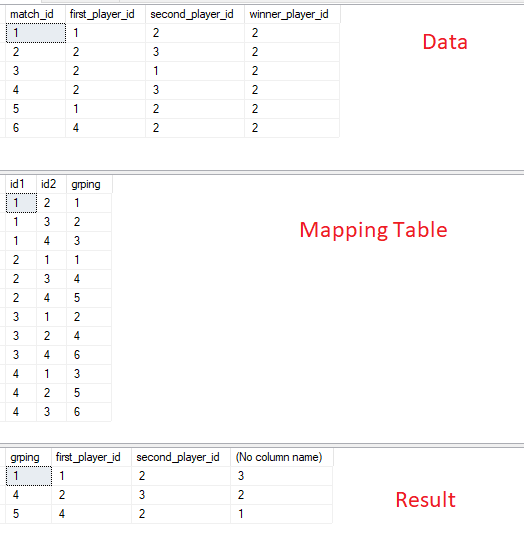
Hi, first of all, am a beginner and would't write here for a rookie question, but I really could handle it out.
Let's say we have this table:
id| first_player_id | second_player_id | winner_id
1 1 2 2
2 2 3 2
3 2 1 2
4 2 3 2
5 1 2 2
6 4 2 2
7 4 2 2
8 4 2 2
9 4 2 2
10 1 2 2
So, my goal is the create a SQL query, that shows versus why a given player_id has most wins.
If I use this:
WHERE first_player_id == 2 and m.winner_id == 2,
group_by: m.second_player_id,
order_by: [desc: count(m.id)],
select: {m.second_player_id, count(m.id)},
limit: 1
that will give us second_player 3 with 2 counts.
Vice versa, if I search for second_player_id == 2, I will get first_player_id = 4 with count = 4
However, If I look for values, where
(first_player_id == 2 or second_player_id == 2) and winner_id == 2
I get see, that vs id 1 there are most matches. How to write this (group by) in SQL?