Convert it when you export the data if you want to / need to. I never said N/Y was a global format. Just that, in SQL Server, N/Y is not that much different from a bit.
I'm not corrupting my SQL Server storage method to suit some outside structure not relevant to SQL.
==== off-topic aside ====
Btw, if you wonder why I say N / Y instead of Y / N, when I code a string of literal values, I code them in alpha order (except in cases where that could lower performance).
So, if I were comparing a list of drives, I would write:
IN ('C', 'F', 'L', 'T')
and never a random order. For a long list, such as acct numbers, this makes it much easier for a human to scan the list, knowing that they are in order.
Just to throw another hat into the ring... and it works just fine in 2008.
If you run the following code, it only takes one pass at the table (3 reads), does no additional reads, doesn't create any table spools, and creates a really cool pattern of data that's really easy to exploit for this problem.
Here's the code...
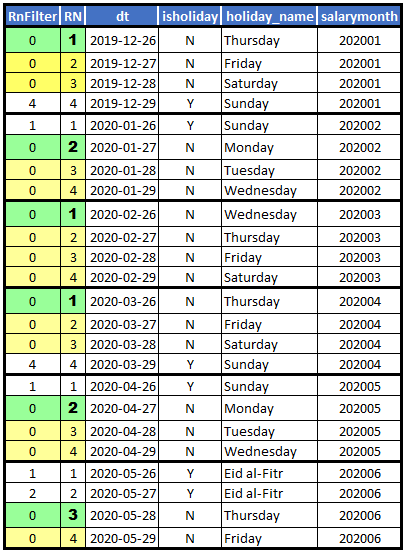
WITH cteEnumerate AS
(--===== Single pass (3 reads) to count the rows in each salarymonth
SELECT RN = ROW_NUMBER() OVER (PARTITION BY salarymonth ORDER BY dt)
,*
FROM dbo.alldates3
)--===== Demonstrate the "sub-grouping" of the RnFilter column
SELECT RnFilter = RN - CASE WHEN isholiday = 'N' THEN RN ELSE 0 END
,*
FROM cteEnumerate
WHERE RN <= 4
;
... and here's the pattern formed. I've colored in the interesting parts...
Notice in the RnFilter column that all of the N's have been converted to "0" and the Y's are all the same as the RN column. That means that all we have to do is find the MIN(RN) for the sub-group of zeros for each salarymonth and subtract 1 from it to find the count of Y's less than that and we still end up with only 3 reads and no spools.
Here's the final code to do that...
WITH cteEnumerate AS
(
SELECT RN = ROW_NUMBER() OVER (PARTITION BY salarymonth ORDER BY dt)
,salarymonth
,isholiday
FROM dbo.alldates3
)--===== Group the isholiday N's into a sub-group,
-- find the minimum RN for each of those sub-groups,
-- and subtract 1 from that to return the number of
-- Y's that are numerically less that than minimum RN.
SELECT salarymonth
,holiday_count = MIN(RN-1)
FROM cteEnumerate
WHERE RN <= 4 --Number of rows to check at the beginning of each salarymonth
AND RN - CASE WHEN isholiday = 'N' THEN RN ELSE 0 END = 0
GROUP BY salarymonth
;
There's another benefit to this code... if someone changes their mind about the number of rows to examine at the beginning of each salarymonth group, all you need to do is change the number in the WHERE clause and you're done!
I'm confused by this. The table has rows for every day. How is a full pass of the table "3 reads"?
Also, you're forcing the entire table to be sorted. Sorts are rather high overhead. Rightly or wrongly, that's why I tried to avoid any ROW_NUMBER() use, since that will always require a sort, which even for a lesser sort requires a memory allocation (as I understand how SQL does a sort).
Finally, personally I think the RNfilter is needlessly complex and thus not easy to follow later.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
I've not looked into why a single scan uses 3 reads... the whole clustered index fits on one page. I suspect that it's one for the original scan, one for the sort, and one for the aggregation but, like I said, haven't looked into it. Still, that number is less than 21 reads.
As for perceived complexity of the RnFilter column, if you think in columns instead of rows, it's not complex but that's also why the SQL Server "gods" allowed comments to be build in to explain... like I did.
Having said that, @ScottPletcher solution is very good
Its all about ideas. The idea presented here did a great thing.
I could construct the codes on my own.
with cte as
(select a.*
, rn = ROW_NUMBER() over(partition by salarymonth order by dt)
from alldates3 a
)
select salarymonth
,holiday_count= min(rn-1)
from cte
where (case when rn>4 then 0 when isholiday='N' then 0 else rn end)=0
group by salarymonth
It is good but it does produce 7 times the number of reads, which is frequently a problem at scale. I'd ask how many rows have you actually tested with but low row count usage isn't a good justification for such issues. Of course, all of our tests have been based on the very small number of rows you've provided... it really does need to be tested at a larger scale.
Thank you for the nice compliment but ... it (both pieces of code) still needs to be tested with a much larger number of rows to be sure. Execution plans change when a larger number of rows is present and folks should always plan on that happening.