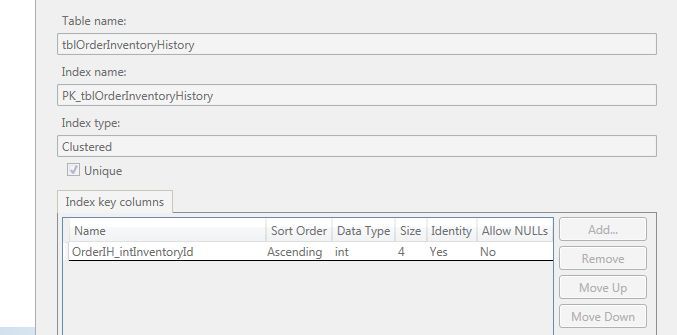
Hello.
I have an issue .
When i do a "SELECT * FROM dbo.tblOrderInventoryHistory" i get a cluster index
but when i do a "SELECT OrderIH_intInventoryId FROM dbo.tblOrderInventoryHistory" i get NON clustered index
How is this possible? Since the index is clustered?
Thanks.
I can force it like this but why it does not understand the clustered index if i don't?
SELECT OrderIH_intInventoryId FROM dbo.tblOrderInventoryHistory with (index = [PK_tblOrderInventoryHistory])
Also another question (if i need to open a new topic let me know).
Is there any difference in performance if i use the one column vs select *
and also any performance benefit if I use top 1 ?
Thanks
SQL will use whichever index it considers to be the most efficient.
SELECT * returns all columns so a table scan is required, and the clustered index will be best for that.
Presumably the [OrderIH_intInventoryId] column in your second query is "covered" by a (non-clustered) index, so SQL can use [just] that index to get the results, which will be faster (fewer disk reads) than scanning the whole table
Yes, definitely faster to use SELECT OneColumn than SELECT * - in fact it is best practice not to use SELECT * - instead name all the columns specifically (even if they are all required). Better than that, name only the columns that are actually used / required by the Client / APP
Otherwise if you add a column to the table, in future, e.g. a "Notes" or "Image" column with huge amounts of data, then ALL queries that use SELECT * will, also, return that column which the receiving APP will not be using and will just discard, so that will consume more effort to retrieve, and much more bandwidth to send to the Client / APP. I did some consultancy for a client who's IT peopel had used SELECT * everywhere, and then added a NOTES column, and performance fell like a stone. It was a huge amount of work to fix, well worth avoiding that trap ...
Also, if you use an explicit column list then there is the opportunity for SQL to use an index that "covers" the whole query - there is potential for a huge performance benefit when that happens
Well ... SELECT TOP 1 will only return one row, so that will be quicker than returning more than one row. If you have an ORDER BY clause, so that the TOP 1 returns the "first" row in the sort order, then most of the time may have been taken up locating the data and sorting it, so the SELECT TOP 1 may not make much difference. Basically if your query would return a lot of rows then SELECT TOP 1 will be much quicker, if the query would only return a small number of rows, and in particular if the columns list is "narrow", then it probably won't make much difference. Big difference to the Client / APP though - either it gets one row ... or several
HI.
Coming back to the * vs 1 column selection.
The execution plan shows less data read on 1 column but the statistics seems to get little higher or with no difference(see trial 4-5-6).
Any thoughts?
This is just academic talk, everything learned is good so...
WHERE OrderH_dtmInitiated >= DATEADD(DD, -3, GETDATE())
AND NOT EXISTS (SELECT OrderH_intID FROM dbo.ZZ_OrdersEmailSent WITH (NOLOCK) WHERE ZZ_OrdersEmailSent.OrderH_intID = OH.OrderH_intID AND (EMailSent = 1 OR RetryStatus >= 300))
And OH.OrderH_strClientClass IN ('WWW','CALL','CELL')
AND (EXISTS(SELECT OrderTH_intTicketId FROM dbo.tblOrderTicketHistory OTH WITH (NOLOCK)
WHERE OTH.OrderH_intID = OH.OrderH_intID AND OrderTH_dtmSessionDateTime >= DATEADD(MINUTE,-60,GETDATE()))
OR (CONVERT(DATE, OH.OrderH_dtmInitiated) >= CONVERT(DATE, DATEADD(dd, -15, GETDATE())) --@DaysToPickup
AND EXISTS(SELECT OrderIH_intInventoryId FROM dbo.tblOrderInventoryHistory OIH WITH (NOLOCK) WHERE ISNULL(OIH.OrderIH_strParentTTypeCode,'') = '' AND OIH.OrderH_intID = OH.OrderH_intID)
AND NOT EXISTS (SELECT OrderH_intID FROM dbo.ZZ_OrdersPickedUp WITH (NOLOCK) WHERE ZZ_OrdersPickedUp.OrderH_intID = OH.OrderH_intID) )
vs
WHERE OrderH_dtmInitiated >= DATEADD(DD, -3, GETDATE())
AND NOT EXISTS (SELECT * FROM dbo.ZZ_OrdersEmailSent WITH (NOLOCK) WHERE ZZ_OrdersEmailSent.OrderH_intID = OH.OrderH_intID AND (EMailSent = 1 OR RetryStatus >= 300))
And OH.OrderH_strClientClass IN ('WWW','CALL','CELL')
AND (EXISTS(SELECT * FROM dbo.tblOrderTicketHistory OTH WITH (NOLOCK)
WHERE OTH.OrderH_intID = OH.OrderH_intID AND OrderTH_dtmSessionDateTime >= DATEADD(MINUTE,-60,GETDATE()))
OR (CONVERT(DATE, OH.OrderH_dtmInitiated) >= CONVERT(DATE, DATEADD(dd, -15, GETDATE())) --@DaysToPickup
AND EXISTS(SELECT * FROM dbo.tblOrderInventoryHistory OIH WITH (NOLOCK) WHERE ISNULL(OIH.OrderIH_strParentTTypeCode,'') = '' AND OIH.OrderH_intID = OH.OrderH_intID)
AND NOT EXISTS (SELECT * FROM dbo.ZZ_OrdersPickedUp WITH (NOLOCK) WHERE ZZ_OrdersPickedUp.OrderH_intID = OH.OrderH_intID) )
Why is number of rows returned by SELECT statements changing at all? Surely that should be constant? (Can the underlying data change during the test? ideally the test would be on a static data set)
... use of NOLOCK always scares me half to death. Scary potential consequences.
Does it matter to your code that EXISTS returns FALSE because NOLOCK causes it NOT to see a row that is actually present? Because, sooner or later, that will happen if rows are being inserted / deleted in tblOrderTicketHistory
Similarly the NOT EXISTS (on ZZ_OrdersEmailSent) will return TRUE for a row that does exist.
Hi.
The number of rows was changing because, after the computation the data is send to the 'ZZ_OrdersEmailSent' and is not calculated.
We are using nolock because we are having a problem when this query is run. Unfortunately it is connected with tables that are used by another company (that, if you remember, we cannot interfere with their tables) and when using the select, we get in a lot of issues on the backbone application of this company and sometimes the software stops responding, so this is a "dirty" solution.
We prefer to loose info on this query rather than losing info or make the main software stop responding.
OK, that's fine - just wanted to be sure you were comfortable with that (and "gain duplicate data" outcome too of course)
I've always used SELECT * for EXISTS ('coz that's what the first textbook said to do! way-back-then my recollection was that "It allows the optimiser to choose which column [index] to use" ... I expect that, now, the optimiser can handle all sorts of syntax, but I'm interested that actually SELECT * might involve MORE I/O or pre-processing or somesuch. I'm happy to adopt a syntax that saves a CPU cycle here and there, it makes no difference to me whether I write SELECT * or SELECT 1 ... or something else.